

Can AMD Bridge Nvidia’s Software Moat?
Transient Moats, Betting on Generative AI, AMD's Path Forward

Nvidia’s dominance is often attributed to various “moats” — competitive advantages that are hard to replicate. Industry observers claim Nvidia’s most important advantage is their CUDA software ecosystem. Yet companies like AMD, Intel, and various startups wake up every day believing they can compete with Nvidia regardless of said moat. Why do these underdogs believe they can overcome the CUDA moat? Let’s dig in.
We’ll first discuss the temporal nature of moats. Then we’ll explore how and why Nvidia built a software moat. Finally, in light of our learnings, we’ll discuss what it will take for AMD to compete.
The Transience of Moats
CUDA's extensive history, the sheer breadth and depth of its offerings, and its massive installed base create the impression of an insurmountable challenge for competitors.
However, are moats truly insurmountable?
After all, can’t a competitor spend their way over a moat?
Warren Buffet and Charlie Munger argue that all moats are temporary.
All moats are subject to attack in a capitalistic system so everybody is going to try. If you got a big castle in there, people are going to try to figure out how to get to it. What we have to decide – and most moats aren’t worth a damn in capitalism, I mean that's the nature of it – but we are trying to figure out what is keeping that castle still standing and what's going to keep it standing or cause it not to be standing in 5, 10, 20 years from now? What are the key factors and how permanent are they? How much do they depend on the genius of the lord in the castle?
Warren says the question isn’t if, but rather how long and why?
There’s widespread agreement that Nvidia's software ecosystem is a durable competitive advantage. But most observers are simply pointing out the existence of the moat or marveling at its size.
When we understand moats to be temporary, we can think differently. A temporary moat is simply a head start, and software generally gives a shorter head start than deep tech.
Let’s explore the factors contributing to the permanence of Nvidia’s CUDA moat.
As an aside: Comparing deep tech moats like ASML’s EUV lithography against software moats would be really interesting. So would the question “what moats do the GPU Rich have, and what happens when AI hardware becomes abundant?” If anyone reading this is thinking about questions like these, email me!
Expansive Ecosystem
Nvidia provides a comprehensive development toolkit – including compilers, drivers, and APIs – that simplifies the task of optimizing algorithms for parallel execution on GPUs. Over time, Nvidia widened the platform’s reach with software development kits tailored to a variety of domains and deepened its capabilities with significant core library and domain-specific optimizations.
The vast breadth and depth of Nvidia's software ecosystem form the bedrock of the CUDA moat argument. Proponents argue it would take a massive amount of manpower for any competitor to catch up to Nvidia’s head start — after all, they began this journey back in 2006 and employ (thousands?) of engineers dedicated to reinforcing this moat.1
These recent job postings demonstrate Nvidia's ongoing investment in deepening their competitive moat:
CUDA Math Libraries Engineer - Image Processing
We are the CUDA Math Libraries team at NVIDIA… We develop image processing libraries that … are used in healthcare, computer vision, deep learning, autonomous vehicles and countless others… Your contributions may include extending the capabilities of existing libraries as well as building new libraries … implementing new image processing algorithms, defining APIs, analyzing performance, finding appropriate solutions for difficult numerical corner cases…
and
Senior Systems Software Engineer, CUDA Trace and Profiling
Join the NVIDIA Developer Tools team and empower engineers throughout the world developing groundbreaking products in AI, Automotive, Gaming, and High Performance Computing… Develop real-time compute performance analysis tools for NVIDIA GPUs running on Linux, Windows, and embedded operating systems… Enable 3rd party tools developers to write sophisticated tools using the profiling API that you develop
The first job focuses on adding depth to a particular CUDA library, and the second expands the breadth of the platform with tools to help third party developers build atop Nvidia.

Let’s dig deeper here and ask why Nvidia built such a vast ecosystem and whether a competitor actually needs to reproduce all of this software to chip away at Nvidia’s moat?
The Evolution of Nvidia's Software Strategy
Recall that GPUs were originally not programmable, but were purpose-built graphic chips. In 2001, Nvidia introduced programmable shaders to their GPUs, marking the beginning of GPU programmability. This feature caught the attention of academic researchers who recognized the parallelism used in graphics rendering was analogous to that needed for scientific calculations such as solving partial differential equations. These researchers hacked the early programmability of GPUs to support parallel processing tasks beyond conventional graphics.2
In 2003, Ian Buck, a Stanford PhD student on a fellowship from Nvidia, led the development of the Brook streaming language which made it easier to write general purpose applications on GPUs. Upon graduation, Ian went to Nvidia and created the Compute Unified Device Architecture (CUDA) which was released in 2006 and ushered in the age of general-purpose computing on Nvidia GPUs. These GPUs picked up the moniker General Purpose GPUs (GPGPUs).
Nvidia rightfully took a platform approach with GPGPUs and built foundational parallel programming libraries to support many different problem domains. For example, here’s Nvidia’s 2011 GPU Technology Conference call for submissions:
If you are pursuing innovative work in parallel computing, we encourage you to submit a proposal in the form of a session or poster submission… Although submitters are not limited to these topic areas, we encourage you to be guided by them.
- Algorithms & Numerical Techniques
- Application Design & Porting Techniques
- Astronomy & Astrophysics
- Audio, Image and Video Processing
- Bioinformatics
- Climate & Weather Modeling
- Cloud Computing
- Cluster Management
- Computational Fluid Dynamics
- Computational Photography
- Computational Physics
- Computational Structural Mechanics
- Computer Graphics
- Computer Vision
- Databases, Data Mining, Business Intelligence
- Development Tools & Libraries
- Digital Content Creation & Film Electrical Design and Analysis
- Energy Exploration
- Finance
- GPU Accelerated Internet
- Life Sciences
- Machine Vision
- Machine Learning & AI
- Medical Imaging & Visualization
- Mobile Applications & Interfaces
- Molecular Dynamics
- Neuroscience
- Parallel Programming Languages
- Quantum Chemistry
- Ray Tracing
- Stereoscopic 3D
- Supercomputing
- Visualization
At the time, the terminal value of any given domain was unclear. Driven by customer demand, Nvidia supported as many domains as possible to see what materialized. This customer-driven platform strategy is also known as “throwing spaghetti at the wall and seeing what sticks”.
It was the correct approach and unlocked a first-mover advantage across many domains, begetting developer inertia.
Nvidia’s platform strategy is summarized in their 2012 annual report:
NVIDIA CUDA is a general purpose parallel computing architecture that leverages the parallel compute engine in NVIDIA GPUs to solve many complex computational problems in a fraction of the time required by a CPU. We are working with developers around the world who have adopted and written application programs for the CUDA architecture using various high-level programming languages, which can then be run at significant execution speeds on our GPUs. Developers are able to accelerate algorithms in areas ranging from molecular dynamics to image processing, medical image reconstruction and derivatives modeling for financial risk analysis. We are also working with universities around the world that teach parallel programming with CUDA as well as with many PC or OEMs that offer high performance computing solutions with Tesla [Tesla is name of an Nvidia GPU] for use by their customers around the world. We also sell directly to supercomputing centers such as Oak Ridge National Laboratory in the U.S. and the National Supercomputing Center in Tianjin, China. Researchers use CUDA to accelerate their time-to-discovery, and many popular off-the-shelf software packages are now CUDA-accelerated.
At the time, Nvidia was touting the following sampling of “killer” apps powered by CUDA: tracking space debris, modeling air traffic, detecting IEDs, reducing radiation from CT scans, operating on a beating heart, simulating shampoo, and cleaning cotton.






Product managers out there will look at that list and ask “how many space junk tracking customers are actually out there, and how many GPUs will they buy?” Enterprise and government solutions generate revenue and buzz but don't drive the chip sales Nvidia needs for true economies of scale.
These are the hard early days of a platform endeavor. The platform has customers with real problems and interesting solutions, but there’s no obvious product-market fit. Companies in this position often attempt to support every incoming customer use case, and prioritization is often a mixture of whoever will pay the most and whichever logo seems most attractive on the “customer stories” page of the website.
Nvidia was clearly still in this discovery stage, exploring the platform's possibilities and seeking out the breakthrough application that would drive massive datacenter GPU demand.
Identifying High-Value Domains and Prioritizing Investments
Nvidia’s early platform sentiment, “there’s value in each of these bets, but it’s not clear which will provide significantly higher returns” reminds me of the dynamics of early-stage venture investing. Early-stage investors bet on scores of startups that all have merit with hopes that a few strike it rich. YCombinator has literally invested in thousands of startups and is sustained by tens of massive winners like Airbnb and Dropbox.
Nvidia’s platform strategy was similar. They bet on a variety of industries with the hopes that something would hit. Early on, the order of magnitude of the terminal value of any given domain was unclear:

At this point in time, any follow-on competitors like AMD faced the uphill battle of entering markets where Nvidia already had a foothold with developers. Overcoming Nvidia’s first-mover advantage would have been a tough task, especially when potential returns were uncertain. It would have been expensive too — competitors would have to rapidly invest the costs that Nvidia distributed over a longer period.
Clearly, copying Nvidia’s “spaghetti against the wall” strategy would have been a futile endeavor.
Product-Market Fit & Winning Bets
If competitors couldn’t match Nvidia's spread, they must instead place fewer bets on the highest-potential domains. Of course the billion-dollar question: where to place bets?
Choosing which domains to bet on would have been very hard in the years B.C. (Before ChatGPT 😂). Fortunately for competitors like AMD, we are into year 2 A.D. (AI Dominance) and the winning bet is suddenly obvious.
Deep-learning is the transformative domain we’ve all been waiting for, and Generative AI is the broad use case with clear paths to consumer-scale adoption.
The expected value of the software bets now looks like the following:
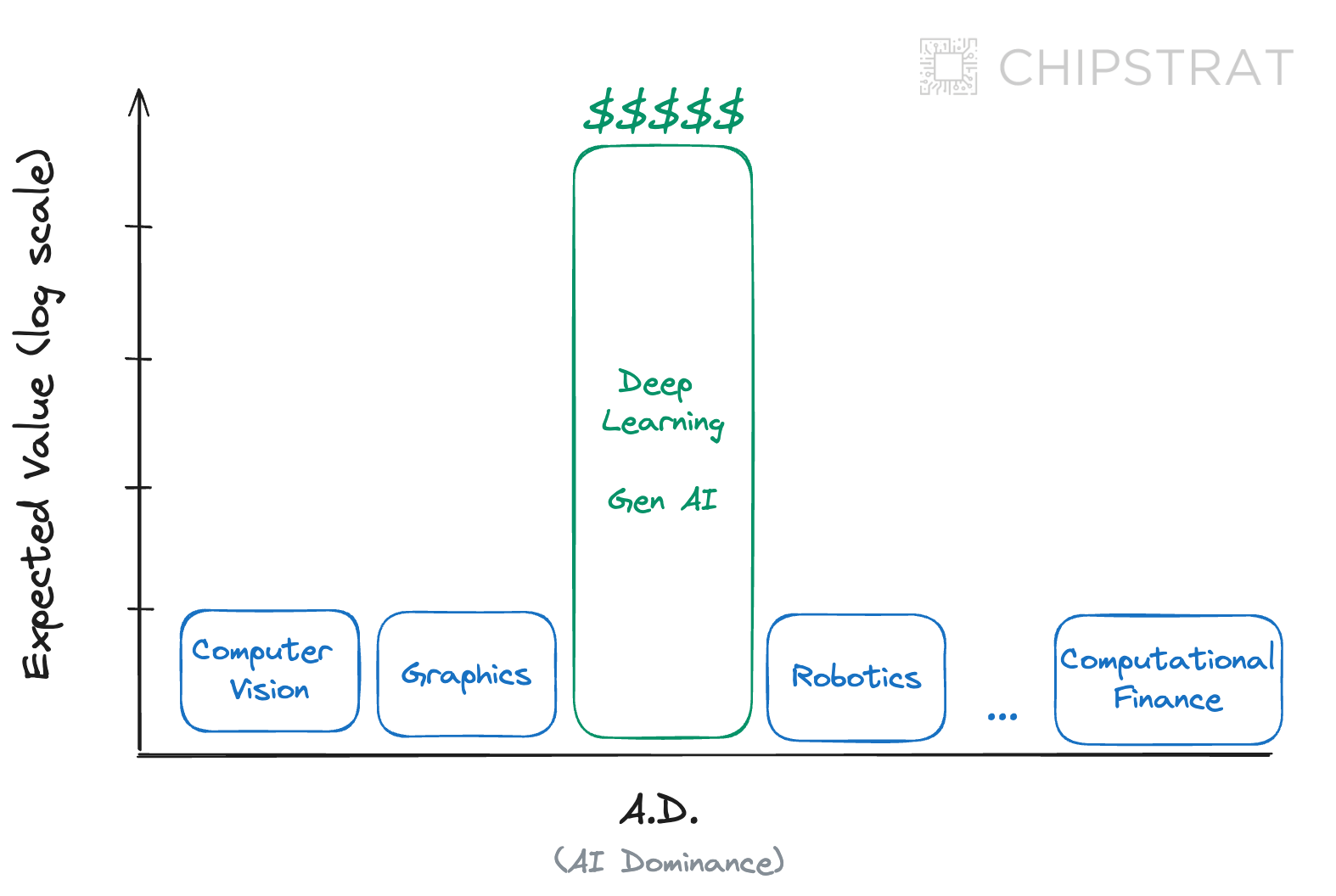
In the next decade, deep-learning enabled Generative AI has orders of magnitudes higher expected value for the hardware industry than other high-performance computing domains. GenAI is the use case that will sell amount of chips needed for economies of scale.
We have product-market fit.
Breaching the Moat
Until now, Nvidia’s software moat seemed well fortified with a huge head start and first-mover advantages.
Paradoxically, in finding product-market fit, Nvidia has revealed the place for competitors to attack.
Specifically, competitors like AMD and various startups including MatX (hello world!) now know where to place their software bets — all-in on Generative AI.
Competitors can build the bridge over the moat by making their hardware run deep-learning based generative AI models as fast / cheap / energy-efficient as possible to unlock the “10-100X better than GPUs” value proposition and entice Nvidia’s customers. They will gamble all of their software engineers’ time on writing the code needed to support GenAI use cases and make it as easy as possible developers to make the switch.
For now, competitors should leave all of the other interesting high-performance computing use cases that have a small number of users for Nvidia to tackle (e.g. computational lithography).
AMD’s Path to Success
Now that Generative AI is the obvious place to invest, AMD is in a much more favorable position than it was a year or two ago.
But they aren’t out of the woods yet. To start, ROCm has a bad rap with developers. And of course, Nvidia still has a major head start, an army of software engineers, and a 10x market cap.
That said, there are opportunities for AMD thanks to abstraction layers, open source, and industry partnerships.

Can AMD actually build a bridge over Nvidia’s software moat and win over developers to build Generative AI use cases on their platform?
Can AMD Overcome Their Software Challenges?
As you likely know if you’ve come this far, AMD has their own software ecosystem called ROCm.

Look familiar? This also looks like throwing spaghetti against the wall.
Although the timing is good for AMD, they are digging out of a hole. The prevailing sentiment from developers is that ROCm is painful to use.
AMD's Current Challenges
From George Hotz’s The Tiny Corp:
The Red Team (AMD)
10 or so companies thought it was a good idea to tape out chips. Ironically, taping out the chip is the easy part. It requires a lot of capital, but that just involves convincing foolish investors that the space they are targeting is SO HUGE that even if they have a 3% chance of success it’s worth investing. Investors fall for this, they invest, and the world tapes out useless AI chips.
There’s a great chip already on the market. For $999, you get a 123 TFLOP card with 24 GB of 960 GB/s RAM. This is the best FLOPS per dollar today, and yet…nobody in ML uses it.
I promise it’s better than the chip you taped out! It has 58B transistors on TSMC N5, and it’s like the 20th generation chip made by the company, 3rd in this series. Why are you so arrogant that you think you can make a better chip? And then, if no one uses this one, why would they use yours?
So why does no one use it?
The software is terrible! There’s kernel panics in the driver. You have to run a newer kernel than the Ubuntu default to make it remotely stable. I’m still not sure if the driver supports putting two cards in one machine, or if there’s some poorly written global state. When I put the second card in and run an OpenCL program, half the time it kernel panics and you have to reboot.
That’s the kernel space, the user space isn’t better. The compiler is so bad that clpeak only gets half the max possible FLOPS. And clpeak is a completely contrived workload attempting to maximize FLOPS, never mind how many FLOPS you get on a real program (usually like 25%).
The software is called ROCm, it’s open source, and supposedly it works with PyTorch. Though I’ve tried 3 times in the last couple years to build it, and every time it didn’t build out of the box, I struggled to fix it, got it built, and it either segfaulted or returned the wrong answer. In comparison, I have probably built CUDA PyTorch 10 times and never had a single issue.
George isn’t the only one, you can find lots of comments all over HackerNews and Reddit of people who desperately want AMD to succeed but are disillusioned by ROCm.
3abiton: I have wasted so many nights debugging and trying to figure out how to get LLMs to run on my AMD iGPU. Despite pytorch and xformers (unofficially) being supported, I was still unsuccessful. Cuda on the other hand, it just works. I don't see the value proposition of AMD over Nvidia for now
and
montebicyclelo: Guessing there are a few of us in a position where we are frustrated with our past experiences with ROCm software, (e.g. being awful to install, in the past there were long guides with loads of steps to follow, and not the greatest clarity / simplicity in the instructions, and the only option they suggested if you messed it up was to reinstall the operating system, and there were multiple guides / pages and it wasn't clear which was the latest one, and then it only supported older versions of tensorflow / pytorch / jax, and only supported recent / higher end cards, etc. — it may be better now, this is my experience from I guess a few years ago); but who at the same time recognise that it would be great for GPU compute to be more affordable, and for there to be good competitors to Nvidia.
and
Cu3PO42: I'm really rooting for AMD to break the CUDA monopoly.… However, AMD desperately needs to do something. Story time:
On the weekend I wanted to play around with Stable Diffusion. Why pay for cloud compute, when I have a powerful GPU at home, I thought. Said GPU is a 7900 XTX, i.e. the most powerful consumer card from AMD at this time. Only very few AMD GPUs are supported by ROCm at this time, but mine is, thankfully.
So, how hard could it possibly to get Stable Diffusion running on my GPU? Hard. I don't think my problems were actually caused by AMD: I had ROCm installed and my card recognized by rocminfo in a matter of minutes. But the whole ML world is so focused on Nvidia that it took me ages to get a working installation of pytorch and friends. The InvokeAI installer, for example, asks if you want to use CUDA or ROCm, but then always installs the CUDA variant whatever you answer. Ultimately, I did get a model to load, but the software crashed my graphical session before generating a single image.
The whole experience left me frustrated and wanting to buy an Nvidia GPU again...
and
sophrocyne: Hey there - I'm a maintainer (and CEO) of Invoke. It's something we're monitoring as well.
ROCm has been challenging to work with - we're actively talking to AMD to keep apprised of ways we can mitigate some of the more troublesome experiences that users have with getting Invoke running on AMD (and hoping to expand official support to Windows AMD)
The problem is that a lot of the solutions proposed involve significant/unsustainable dev effort (i.e., supporting an entirely different inference paradigm), rather than "drop in" for the existing Torch/diffusers pipelines.
To be fair, most of these use cases are tinkerers trying to run LLMs on personal computer gaming cards, not HPC cards like MI300X. That said, some of these tinkerers are likely the type of people who are doing the same at their day job or could be open-source contributors adding to AMD’s ecosystem.
Nvidia’s CUDA is supported on nearly every GPU since 2006, from desktop gaming cards to datacenter compute chips. When tinkerers try to run inference on their gaming cards, it “just works”.
AMD's Opportunities - Abstraction & Open-Source
At this point in our analysis, things aren’t looking good. AMD has ROCm and its poor reputation, a small user base, and a less developed ecosystem. Nvidia’s CUDA “just works”, a broad ecosystem, loads of employees fortifying the moat, and an ~8x greater market cap.
Is it hopeless for AMD? No!
To start, ROCm isn’t the layer where most of the inference and training code is written. Much code is written at a level of abstraction higher, including PyTorch, Tensorflow, and JAX.
Furthermore, code at this level of abstraction can often run on environments from different vendors, making it easier for developers to move off Nvidia.

These higher-level abstractions are open source, which leads to my next point.
AMD has an important, strategic trick up their sleeve: the open-source community.
Nvidia’s CUDA is closed source. As a developer, you get what Nvidia gives. If you need a feature, let Nvidia know and hope they support it. If there’s a bug, let Nvidia know and hope they fix it.
But with open source ROCm, knock yourself out! If you need a feature, build it! If you find a bug, fix it. See this example.
AMD must empower developers with great documentation and encourage them to contribute their own enhancements and fixes back to the core repository.
Interestingly, the totalilty of “Gen AI software” might soon shift to mostly client app code (e.g. mobile and web apps) integrating with inference APIs provided by giants like Azure OpenAI, Nvidia NIMs, or specialist hardware companies like Groq.
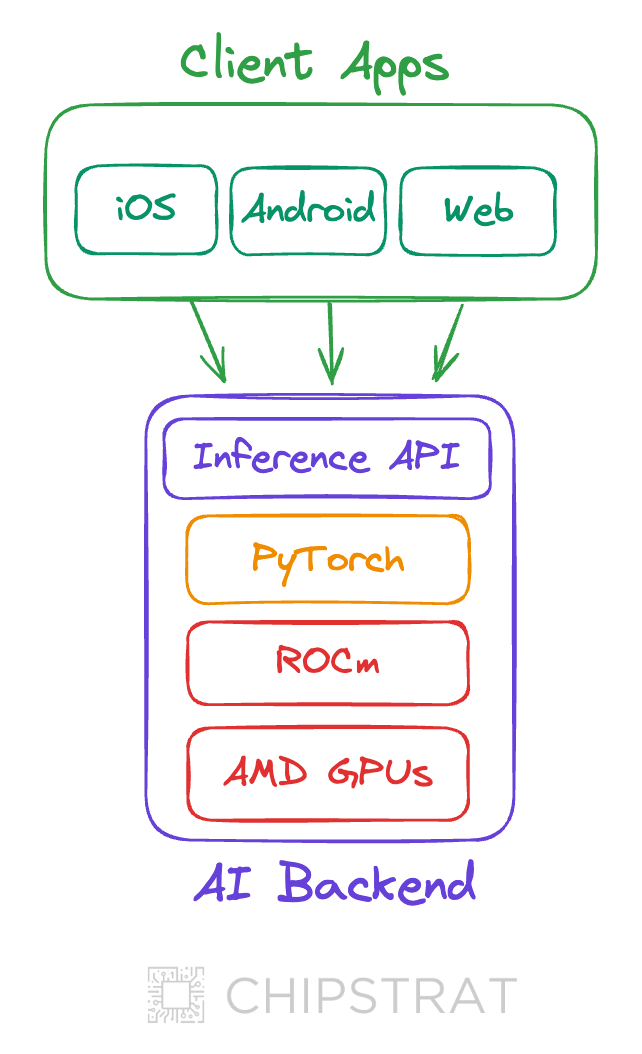
Thus, the totality of new ROCm code may be small compared to higher levels of abstraction, for example the amount of code may increase up the stack: ROCm < PyTorch < Inference APIs < Client Apps
In this scenario, the amount of any given developer’s (potentially painful) interaction with ROCm could be minimal. Most devs can simply focus on integrating inference APIs into their new or existing mobile apps. AMD can limit the scope of “fixing ROCm” to that which is needed to support inference APIs atop AMD hardware.
AMD's Strategic Focus - Developer Experience and Performance
How should AMD proceed?
AMD must go all in on the end-to-end developer experience for GenAI on top of ROCm and AMD GPUs. They must dogfood internally by creating cross-functional teams that build client apps on top of an AMD/ROCm inference stack and fix all of the painful issues along the way. Reduce the number of employees contributing to other HPC domains and move them to these prioritized GenAI swat teams.
Many existing open-source ROCm libraries, especially scientific computing, have repos already maintained by external developers like academics. You’d be surprised what a grad student or home tinkerers will do for free swag and public gratitude — take advantage of that!
In an EE Times interview with Sally Ward-Foxton, AMD Sr VP of AI Vamsi Boppana made it clear that ROCm is the highest priority across the company.
AMD has made ROCm the No. 1 priority at the company level in the last year, Boppana said, standing up a new organization that’s brought together assets from all the company’s software contributions.
“We have much larger resources actually working on software, and [AMD CEO Lisa Su] has been very clear that she wants to see significant and continued investments on the software side,” Boppana said. “We have agreed to provide people internally, we have acquired Mipsology, and we are looking to grow talent both organically and inorganically.”
AMD also recently stood up an internal AI models group to increase its experience using its own software stack.
“We want a much tighter feedback loop,” Boppana said.
It’s promising that AMD is standing up their own team to dogfood internally.
Shifting Developer Sentiment
Why prioritize developer experience so heavily?
For AMD to succeed, they need adoption and retention. AMD will garner adoption via their performance-per-cost value proposition (good performance, lower cost) — but as we’ve seen, ROCm prevents retention. Hardware performance is important, and can rightfully become the focus once the developer experience roadblock is removed.
AMD should set company-wide goals around ROCm developer ease-of-use, specifically for end-to-end inference and training workloads with the most popular LLM software like PyTorch.
AMD could align teams around GenAI developer experience and performance metrics. For example (timeframes may not be reasonable, just spitballing for illustration)
Reduce the incidence of kernel panics and system crashes by 75% when running PyTorch models on ROCm within two quarters.
Reduce onboarding time for developers new to ROCm with PyTorch on AMD GPUs by 50% within one quarter.
Grow the external contribution to the ROCm platform by 50% within one year through active community engagement and incentives.
Achieve a 25% quarter-over-quarter improvement in developer satisfaction as measured by net promoter score (NPS).
Increase the performance of PyTorch models on ROCm to reach at least 80% of the performance achievable on competitive platforms within one year.
These goals could drive tasks such as:
Create an official channel for ROCm support, with a commitment to resolve common issues within 48 hours.
Create comprehensive, clear, and streamlined documentation that enables developers to set up their development environment within 2 hours.
Develop and release a suite of tools for debugging and performance analysis tailored to common workflows in PyTorch on ROCm.
Implement a quarterly survey to capture developer feedback and track improvements in the ROCm experience.
Conduct regular (biannual) benchmarking and publish performance reports to demonstrate gains.
Partner with at least three major entities in the AI and ML field to validate and enhance the ROCm ecosystem for broader use cases.
Collaborate with key stakeholders to ensure the OpenXLA project supports and prioritizes AMD GPUs
AMD's Internal Initiatives
The good news is that, at least with new hires, AMD appears to be quite focused on improving the software support for GenAI training and inference.
Recent job descriptions discuss cross-functional efforts to optimize inference and training up and down the AMD stack
Work with cross-functional teams to analyze performance gap and optimize various parts of the Al SW stack - kernel, compiler, frameworks, device drivers, and firmware.
Conduct benchmarking and performance analysis of various MLOps solutions on AMD Instinct across metrics like time-to-train, cost efficiency, ease of use to drive recommendations.
Maintain pulse on latest innovations from AMD: hardware, compilers, drivers relevant to ML training, deployment, inference - and bridge communication across engineering orgs.
Leveraging Open Source Partnerships
Another key step in this journey is leveraging open source partnerships with other major companies seeking to improve the GenAI user experience for developers on non-Nvidia hardware.
Google OpenXLA is an open source compiler that takes AI models built in popular frameworks like PyTorch, TensorFlow, and JAX and makes them run efficiently on different types of hardware like AMD GPUs.

While simplifying developer transitions to and from AMD might seem counterintuitive, it's a good move. Since AMD currently has a smaller developer base, making it easier to adopt their technology is crucial for growth.
This focus on code portability forces competition back to the fundamentals – hardware capability and price – areas where AMD excels.
AMD’s existing developer base has already demonstrated commitment by overcoming the friction of running software on AMD, clearly attracted by AMD’s lower cost hardware. With XLA reducing the friction of moving to another platform, it’s unlikely these devs are going to leave. But it is very likely that new devs will come over from Nvidia.
Finally, as a society we should aim to make GenAI development more accessible and affordable. Code portability between hardware vendors breaks down barriers, fosters competition, and ultimately lowers costs. This marketing narrative is one that every hardware company, with the exception of Nvidia, can rally behind to garner public support.
Low Cost Value Proposition
What happens if AMD can make GenAI software development much simpler? AMD will chip away against Nvidia with a “low cost” value proposition.
We are seeing glimpses of this already.
Remember George Hotz and Tiny Corp? They made AI on AMD work (with much friction and effort) and are selling an AMD high-performance computing system at a 40% lower cost than Nvidia:
A hard to find "umr" repo has turned around the feasibility of the AMD tinybox. It will be a journey, but it gives us an ability to debug.
We're going to sell both, red [AMD] for $15k and green [Nvidia] for $25k. When you realize your preorder you'll choose your color. Website has been updated.
If you like to tinker and feel pain, buy red. The driver still crashes the GPU and hangs sometimes, but we can work together to improve it.
Going to start documenting the 7900XTX GPU, and we're going right to the kernel in tinygrad with a KFD backend. Also, expect an announcement from AMD, it's not everything we asked for, but it's a start.
If you want "it just works" buy green. You pay the tax, but it's rock solid. Not too much more to say about it. Compare to more expensive 6x4090 boxes elsewhere.
Hopefully we get both colors of tinybox on MLPerf in June.

Hotz clearly articulates the state of affairs: AMD costs significantly less but comes with significantly more headaches. Nvidia can remove those headaches, but for a significant premium.
If AMD can reduce those software headaches they will be a much more compelling offering.
Conclusion
Generative AI has presented a clear focus area for AMD to place their bets, and the longevity of Nvidia's software moat has been reduced.
Yet AMD's success requires relentless focus on improving the developer experience for common GenAI stacks atop ROCm. Additionally, AMD should actively nurture an open-source community around ROCm and pursue partnerships like Google's OpenXLA to increase their leverage.
If AMD can significantly reduce the friction of using their hardware for GenAI, their GPU cost advantage could become a compelling proposition, shifting the competitive focus back to performance and price.
I’d love to see AMD muscle through the software issues, win over developers, and compete on performance and price with Nvidia.
Yes, Nvidia has other moats, but that’s a story for another day.