

Data Center Energy, National Security, Nuclear Power
OpenAI's Training and Inference Scaling Laws Call For More Nuclear Power

From Bloomberg:
OpenAI has pitched the Biden administration on the need for massive data centers that could each use as much power as entire cities, framing the unprecedented expansion as necessary to develop more advanced artificial intelligence models and compete with China.
OpenAI said investing in these facilities would result in tens of thousands of new jobs, boost the gross domestic product and ensure the US can maintain its lead in AI development, according to the document, which was viewed by Bloomberg News. To achieve that, however, the US needs policies that support greater data center capacity, the document said.
Let’s explore why massive data centers are inevitable, and so is government involvement.
Dual Scaling Laws
OpenAI's seminal research showed that LLMs improve with increased computation, model size, and dataset size during training.
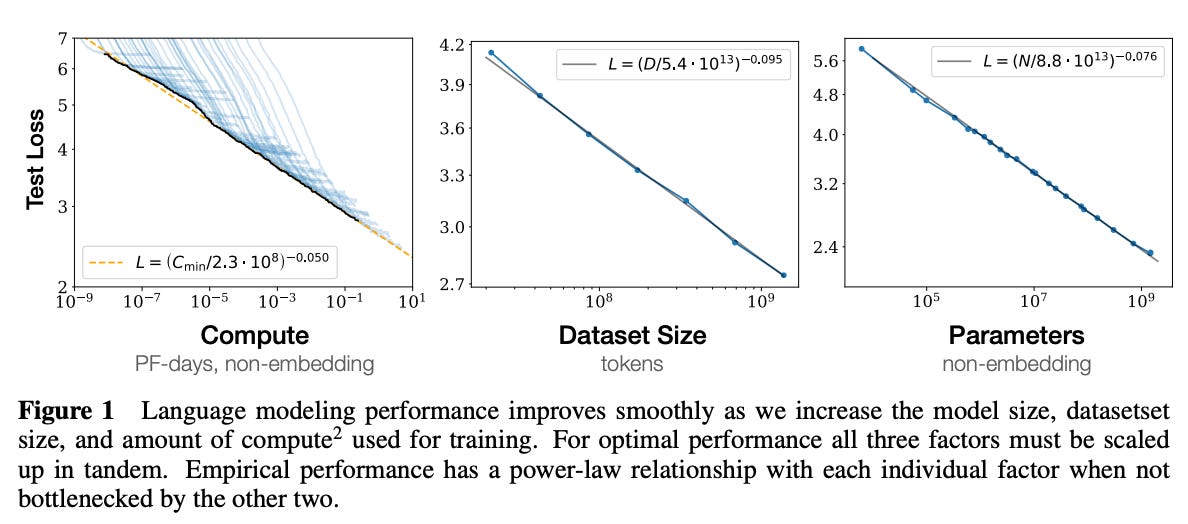
This training scaling law has shown no signs of plateauing yet.
OpenAI recently revealed an inference scaling law stating that reasoning models like o1 can significantly improve performance when given more time to think (perform additional internal reasoning steps).

(As a quick reminder, these “laws” are observations like Moore’s Law, not fundamental laws like Newton's Law of Universal Gravitation.)
These dual scaling laws have significant implications.
It’s reasonable to presume the training scaling will asymptote sooner or later; it’s just a matter of when. Yet the rise of reasoning models that obey inference scaling provides a path for continued advancement beyond training scaling limits.
This is a bullish sign for continued AI CapEx investments by foundation model companies. Imagine a company that builds a massive GPU cluster of Nvidia’s B100s and doesn’t see as much increased model performance as expected from its training runs. It may have ventured into the asymptotic portion of the training scaling law, but that doesn’t mean it’ll stop acquiring AI accelerators. Instead, the company will shift its R&D efforts and CapEx to throwing more compute at inference until it maxes out on that front, too.
It’s also bullish for enterprise investments. Most companies aren’t massively training (pretraining frontier models), but they are inferencing. This inference scaling law suggests a future of increasing computation needs for everyone, not just frontier model companies.
The value of AI models is the intelligence they offer to new or existing solutions. Any solution that leverages o1-like reasoning engines can now access increased intelligence by adding more test-time computation. Thus, enterprises and startups that embed GenAI intelligence in their products can control how much intelligence they can squeeze out of a model by deciding how much test-time computation they want to pay for. This is a new level of control for companies using GenAI in their products!
It’s also a new business model opportunity for OpenAI and others. API users who need the highest intelligence could pay more for increased test-time computation.
For the foreseeable future, the big hyperscalers and AI labs will continue increasing their total computation spending until the asymptotes are reached for both scaling and inference laws.
Given inference scaling laws, enterprises may spend more, and for longer, than previously expected. Nvidia bulls rejoice!
Unlocking More Computation
How will companies acquire the increasing computation needed to scale training and inference?
Buy Better Chips
The most straightforward approach is to continue buying increasingly powerful chips. This approach benefits from Moore’s Law and the continued hardware and software innovations from Nvidia. We see this in practice today — a system with 8 H100s can execute more FLOPs than a system with 8 A100s.
Of course this simplistic approach is limited by Nvidia’s design cycle and TSMC’s manufacturing cadence. New chips only debut once every one or two years and new semiconductor manufacturing processes launch every two years or so.
Even with this cadence, supply remains limited as production ramps up, so there’s an allocation constraint—who gets priority as chips leave the fab? Hyperscalers do because they buy the most chips. This implies only hyperscalers experience the fastest hardware innovation cycles; everyone else waits longer. Simply waiting for better chips isn’t the best strategy to keep up with the pace of AI innovation.
Buy More Chips
Another approach is to use more chips.
Why use 1K chips for training when you can use 10K? Why use 10K when you could use 100K?
Building such massive data centers is time-intensive. It involves securing real estate and power, which generally require local government oversight to meet local zoning and environmental standards.
Managing large GPU clusters at scale also presents significant operational challenges. Hardware failures increase as the system grows, requiring a “healing buffer” of idle GPUs set aside as a backup. The orchestration of training across the cluster becomes quite complex, leading to inefficiencies and suboptimal use of the entire cluster. A large GPU cluster might only actually use 80% of GPUs, and even then, it might only reach 20-50% Model Flop Utilization (MFU) during training due to issues like memory bandwidth constraints and communication overhead.
More and Better
Companies pursuing frontier model training combine both approaches to keep up with scaling laws — buy better chips, and more of them.
More and Better Chips = More Energy
AI accelerators turn energy into intelligence. Obviously, data centers need power.
These accelerators also need to communicate with others in the cluster. This communication requires energy, too.
I forgot to mention that heat is a byproduct of all this computation and communication — AI accelerators turn energy into intelligence and heat.
Thus, AI accelerators need to be cooled. As you guessed, cooling chips requires energy too.
Thus, AI data centers require a lot of energy for computation, communication, and cooling.
How Much Energy?
How much energy does a modern AI accelerator data center consume?
Most AI accelerator data centers are built by hyperscalers or private GPU cloud providers, so public information is scarce.
However, we can look to Applied Digital Corporation (APLD) for insight. APLD is a relatively new company that designs, develops, and operates modern data centers. For interesting historical reasons, APLD is already publicly listed, so we can find information about its data center buildouts that it chooses to share with investors.
Applied Digital’s 10K states they are building a 100 MW data center in Ellendale, ND. This facility is purpose-built for GPUs and approaches the limit of GPUs that a single building can support, so APLD is looking to add two more buildings to their campus.
The Company has entered into exclusivity and executed a letter of intent with a US-based hyperscaler for a 400 MW capacity lease, inclusive of our current 100 MW facility and two forthcoming buildings in Ellendale, North Dakota
Generally, if modern data center buildings are on the order of ~100MW, modern campuses might be hundreds of MW up to a thousand MW. 1GW is 1000MW.
Dual scaling laws suggest that data center campus power needs will rise to 500-1000MW and beyond.
Need More Power
The next natural question is whether the United States power grid can support new data center campuses that need hundreds of MWs of power.
It turns out some locations are already tapped out. According to DCD,
Existing markets are already struggling to meet demand, the report says. In Northern Virginia, the largest data center market in the world at 3,400MW, availability is running at just 0.2 percent.
Other popular areas face similar challenges, the report says, with availability in the Bay Area around San Francisco running at 0.5 percent of capacity, while availability in Dallas Forth Worth is 1.9 percent and in Phoenix, Arizona, it’s 3.8 percent.
The lack of available power forces data center developers to find alternative sites.
Power, water, land, and fiber are abundant where I live in Iowa, and as a result, we have data centers from companies like Microsoft, Meta, and Apple in our backyard. As Microsoft explains,
For the past few years, Microsoft has been powering the future of AI from a cluster of datacenters located amidst sprawling farmlands and rural roads in Iowa.
Yet even in places where the necessary ingredients are available, building new data centers can be slow due to a limited supply of power infrastructure like transformers and transmission lines.
One cheat code is simply to buy access to a nuclear power plant. AWS recently acquired a data center campus at a nuclear power station in Pennsylvania. DCD writes,
The 1,200-acre campus draws power from Talen Energy’s neighboring 2.5GW nuclear power station in Luzerne County. Talen said AWS aims to develop a 960MW data center campus.
960MWs! That’s what we need for scaling!
How Much Power OpenAI Wants
While modern data centers are on the order of 100MW, OpenAI is pitching the government on data centers that require an order of magnitude more energy — 5GW. This is big enough to power major cities.
In June, John Ketchum, CEO of NextEra Energy Inc., said the clean-energy giant had received requests from some tech companies to find sites that can support 5 GW of demand, without naming any specific firms. “Think about that. That’s the size of powering the city of Miami,” he said.
Why 5GW?
According to SemiAnalysis, “the critical IT power required for a 100k H100 cluster is ~150MW.”
Assuming linear scaling, a 5GW power capacity could theoretically support 3 million H100s. Given power distribution losses, cooling demands, and infrastructure overhead of such an enormous campus, it’s reasonable to assume 3 million GPUs is an overestimate. But even if we’re talking 1 million GPUs, this order of magnitude is still incredibly large.
Sam Altman is pitching the idea of a single data center campus that could support upwards of 1 million GPUs and eventually replicate that to several locations.
Joe Dominguez, CEO of Constellation Energy Corp., said he has heard that Altman is talking about building 5 to 7 data centers that are each 5 gigawatts. The document shared with the White House does not provide a specific number. OpenAI’s aim is to focus on a single data center to start, but with plans to potentially expand from there, according to a person familiar with the matter.
OpenAI wants to increase computation by several orders of magnitude, as predicted by the dual scaling laws.
Dylan Patel at SemiAnalysis revealed that 25,000 A100s were used to train FPT-4 (with ~33% MFU), which is 2E25 FLOP of computation. He then pointed out how the next generation of models will require an order of magnitude more computation:
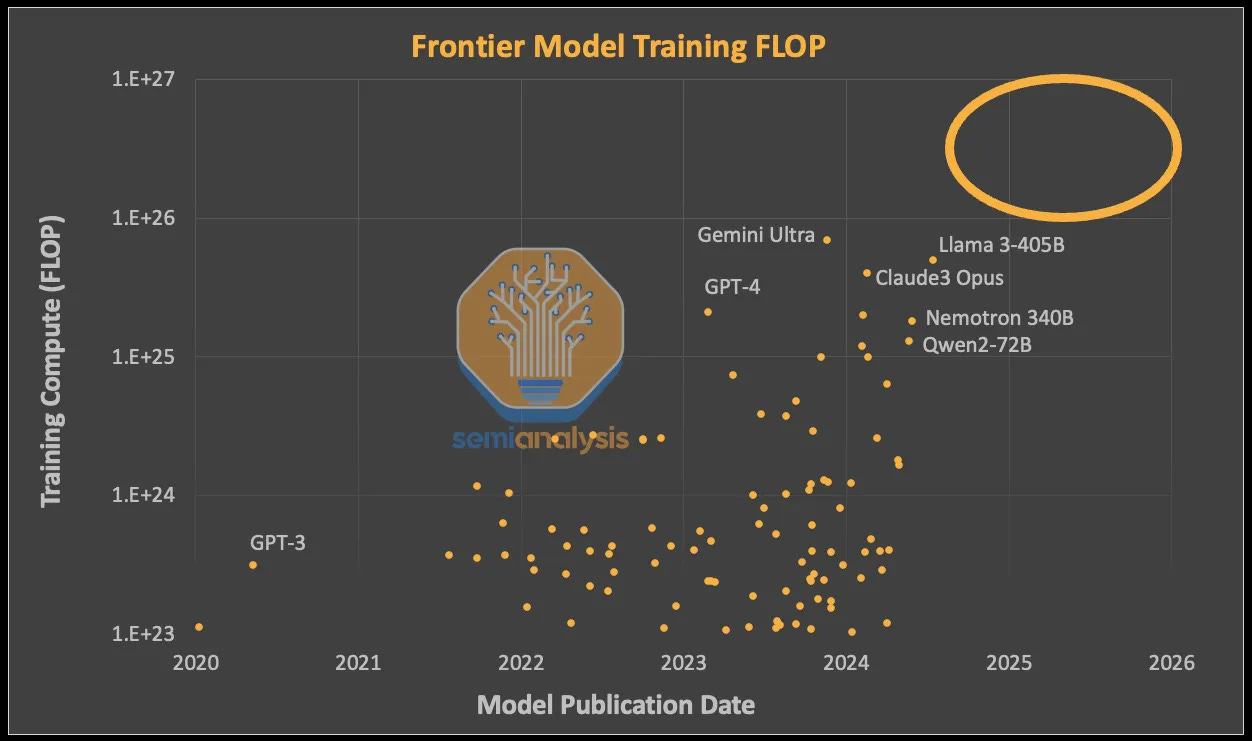
This chart raises questions like “How big must a cluster be to reach 1E26 FLOP?” and “How much power will that many GPUs require?”
Government Involvement
These questions get to why Altman is seeking the Biden Administration’s help.
5GW campuses will require significant power and real estate.
That much power would require a mix of new wind and solar farms, battery storage and a connection to the grid, Ketchum said. He added that finding a site that could accommodate 5 GW would take some work, but there are places in the US that can fit one gigawatt.
While cleaner than coal and natural gas, an approach combining renewables and batteries on this scale is challenging and surely expensive.
“Whatever we’re talking about is not only something that’s never been done, but I don’t believe it’s feasible as an engineer, as somebody who grew up in this,” Dominguez told Bloomberg News. “It’s certainly not possible under a timeframe that’s going to address national security and timing.”
A better solution is nuclear – it’s clean and surprisingly abundant in the US, accounting for nearly 20% of electricity generated.
My hunch is that OpenAI is laying the groundwork with the Biden administration for conversations regarding nuclear-powered data centers.
Building entirely new nuclear plants has historically been off the table, but there’s recent precedent of adding new reactors at existing sites:

Of course, acquiring or developing nuclear takes time, government blessing, and a ton of money. From EIA, the recent reactor installations were slow and expensive.
Construction at the two new reactor sites began in 2009. Originally expected to cost $14 billion and begin commercial operation in 2016 (Vogtle 3) and in 2017 (Vogtle 4), the project ran into significant construction delays and cost overruns. Georgia Power now estimates the total cost of the project to be more than $30 billion.
Interestingly, these two reactors bring the plant’s total capacity to nearly 5GW, exactly what Altman is asking for!
The two new reactors bring Plant Vogtle’s total generating capacity to nearly 5 gigawatts (GW), surpassing the 4,210-MW Palo Verde plant in Arizona and making Vogtle’s four units the largest nuclear power plant in the United States.
5GW?! Now we’re cooking with gas!
“Now we’re cooking with gas” originated in the mid to late 1930s as an advertising slogan thought up by the natural gas industry to convince people to use gas, rather than electricity, to power their kitchen stoves. —Walton Gas
Hey marketers in the nuclear industry, time to create a new phrase! 😂
National Security
What’s in it for the government? We’re in an intelligence arms race, and we can’t afford to lose.
Yes, we need chips to turn power into intelligence (CHIPS Act), but we also need power!
Power will be the limiting factor for the foreseeable future.
By the way, which country is building the most nuclear? China!

Scaling laws → massive data centers → significant energy → nuclear.
Ergo, government help. Such endeavors involve lots of regulatory approval and money.
Could a nuclear industry equivalent to the semiconductor industry’s CHIPS Act be an option?
Do We Actually Need 5GW?
One might ask if we actually need 5GW data center campuses.
What if we see AI accelerators that are 10x more performant than today’s GPU-based systems? Think Etched and MatX and, eventually, Nvidia and AMD. Between architectural innovations, networking and memory improvements, and Moore’s Law, future data centers may need fewer AI accelerators than currently projected to unlock that subsequent order of magnitude in FLOPs training. In return, they would need less power — say, 500MW instead of 5GW.
Of course, given the dual scaling laws, the industry won’t stop at 1GW! They’ll simply reach the next model size more power-efficiently. Until both scaling laws fall apart, we’ll keep going! 😅
No matter how power efficient and performant our systems get, we’ll want more computation.
Power is the Limiting Factor
If we scale until we can’t, is money the ultimate limiting factor? Won’t CapEx limit how far any individual company can go alone? Who can pay for $100B of AI compute?!
First, market forces should continue to drive down the cost of intelligence.
But if national security is at stake, money may not be the limiting factor. The government could step in with subsidies and tax incentives.
Energy production is the true limiting factor.
Hence Sam Altman’s trip to Washington DC.