



DeepSeek Mixture of Experts & V2
Rewinding: DeepSeek’s 2024 research and its impact on the semiconductor industry

We previously looked at DeepSeek’s reasoning model R1 and distilled variants. I started with the reasoning model because it could upend OpenAI’s business model, which seems to be playing out:

Yet a lot of investors freaked out because of the V3 paper. So I set out to break down DeepSeek’s V3 paper, but soon realized we needed first to cover V2 for context.
So, in this post, we'll rewind to 2024 and explore the key innovations that paved the way for DeepSeek's V3 paper.
V2 - A Strong, Economical, and Efficient Mixture-of-Experts Language Model
From the paper's title, we can tell right away that DeepSeek is focused on cost and performance efficiency.
This is emphasized in the first paragraph:
In the past few years, Large Language Models (LLMs) (Anthropic, 2023; Google, 2023; OpenAI, 2022, 2023) have undergone rapid development, offering a glimpse into the dawn of Artificial General Intelligence (AGI). In general, the intelligence of an LLM tends to improve as the number of parameters increases, allowing it to exhibit emergent capabilities across various tasks (Wei et al., 2022). However, the improvement comes at the cost of larger computing resources for training and a potential decrease in inference throughput. These constraints present significant challenges that impede the widespread adoption and utilization of LLMs. In order to tackle this problem, we introduce DeepSeek-V2, a strong open-source Mixture-of-Experts (MoE) language model, characterized by economical training and efficient inference through an innovative Transformer architecture.
DeepSeek emphasizes the trade-off between increased AI intelligence requiring larger models and the resulting challenges of slower inference and higher compute needs. This is the motivation behind V2 — can we unlock more intelligence from our silicon and serve it without negatively impacting user experience?
This “model size vs. inference performance” trade-off is important, so I’ll unpack that first. Skip ahead if you’re already familiar.
Model Size vs. Inference Speed
Pre-training scaling laws teach us that simultaneously increasing model size, training dataset size, and compute boosts intelligence.
However, larger models require more computations, resulting in slower inference.
Neural networks rely on matrix multiplications, and the matrices and vectors grow in size as the model grows. For example, Y = Wa + B, where W is the weights matrix, a is the activation vector, and b is the bias vector.
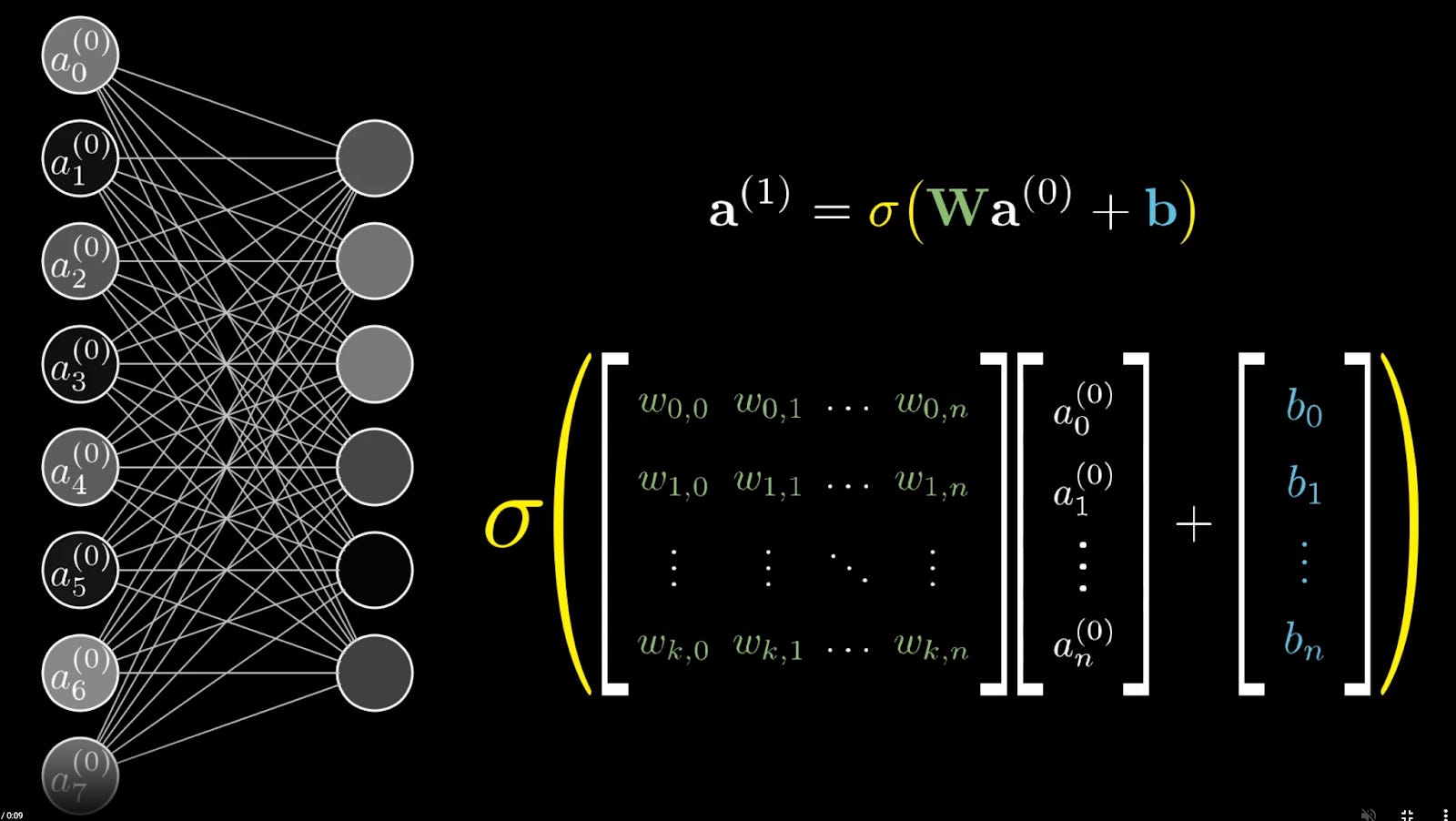
Increasing the number of layers in a neural network expands W by introducing more connections. Increasing the number of neurons per layer enlarges both a and b since more neurons generate more outputs and require additional biases.
Thus, larger models require larger matrices, leading to increased computation.
Why more FLOPs?
Matrix multiplication consists of multiple dot products, which involve element-wise multiplications followed by summation:

Matrix multiplication is simply a collection of dot products:

If the matrix is bigger than 2x2, no problem — just more multiplication and addition for each dot product.

Computers excel at multiplying and adding, and dot products are efficiently executed using multiply-accumulate (MAC) units.
These independent dot products can be computed in parallel, which is where GPUs, NPUs, and AI accelerators shine—performing thousands of multiply-accumulate (MAC) operations concurrently.
Key takeaway: As a neural network grows, its matrices expand, demanding more multiply-accumulate operations. If all MAC units are fully utilized, additional operations spill into extra clock cycles, increasing inference latency.
Quadratic Slowdown
Unfortunately, LLM computational cost scales quadratically with dimension size, driving up FLOPs in both the feedforward network and attention mechanisms. (See this great resource to learn more).
In layman’s terms, increasing the model size can drastically impact time a user waits for the LLM to respond.
Mixture of Experts
OK, back to the V2 paper.
These constraints present significant challenges that impede the widespread adoption and utilization of LLMs. In order to tackle this problem, we introduce DeepSeek-V2, a strong open-source Mixture-of-Experts (MoE) language model, characterized by economical training and efficient inference through an innovative Transformer architecture.
Here’s a quick refresher on Mixture of Experts—skip if you’re already familiar.
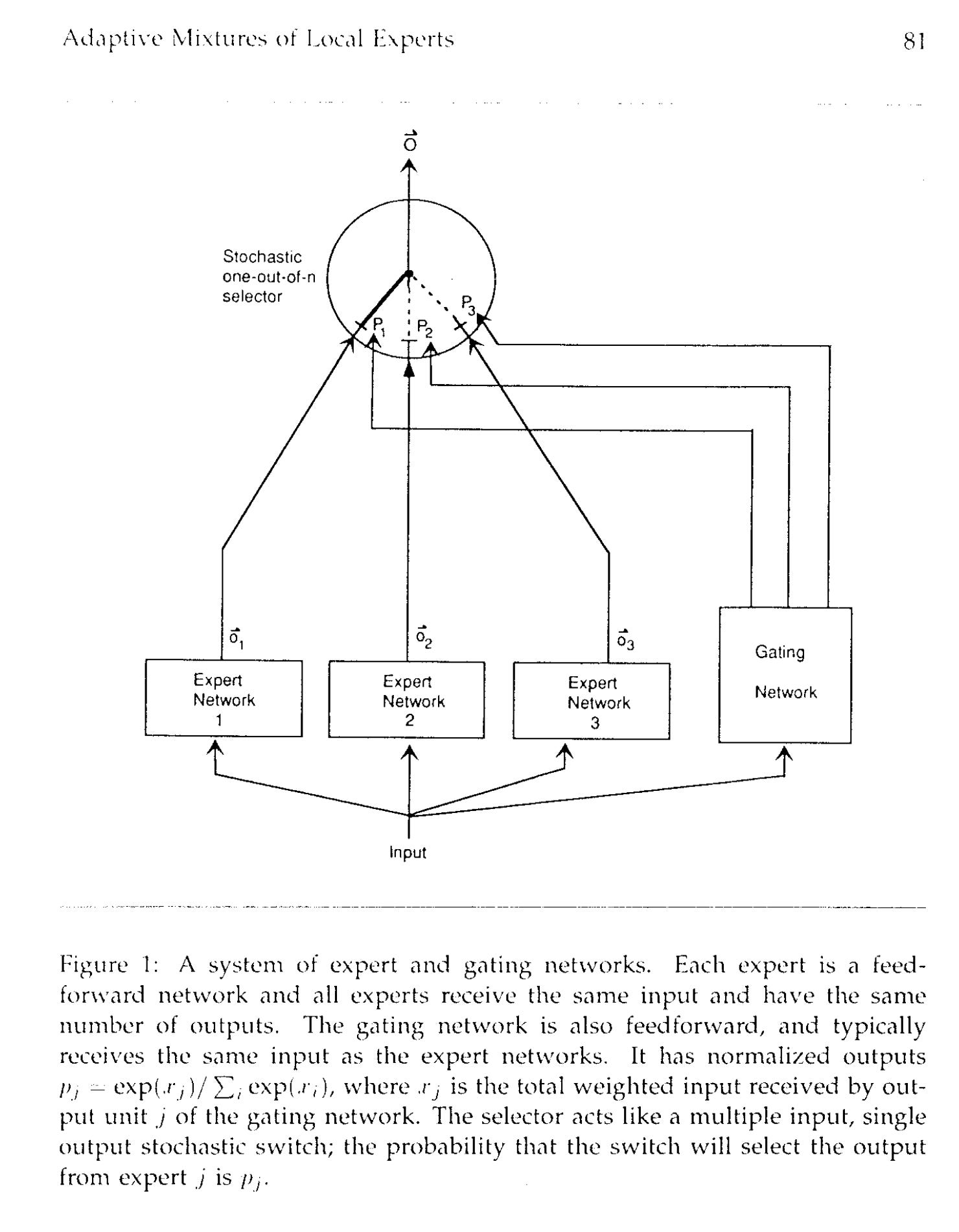
Mixture of Experts is an architecture that divides a problem into sub-tasks handled by experts (specialized neural networks) with a mechanism to determine which expert to activate for a given input. This architecture traces back to this 1991 “Adaptive Mixture of Local Experts” paper from several AI forefathers including Geoffrey Hinton.
You may recall Mistral’s Mixtral of Experts announcement in Dec 2023 and subsequent Jan 2024 paper.
Mixtral is a sparse mixture-of-experts network. It is a decoder-only model where the feedforward block picks from a set of 8 distinct groups of parameters. At every layer, for every token, a router network chooses two of these groups (the “experts”) to process the token and combine their output additively.
> This technique increases the number of parameters of a model while controlling cost and latency, as the model only uses a fraction of the total set of parameters per token. Concretely, Mixtral has 46.7B total parameters but only uses 12.9B parameters per token. It, therefore, processes input and generates output at the same speed and for the same cost as a 12.9B model.
The MoE architecture is efficient because it only uses a subset of the neural network for each token. So yes, you need to load the entire network (46.7B parameters) into memory, but for each token only 2 of 8 experts are used (12.9B parameters).
Conceptually, Mistral’s architecture is like this:
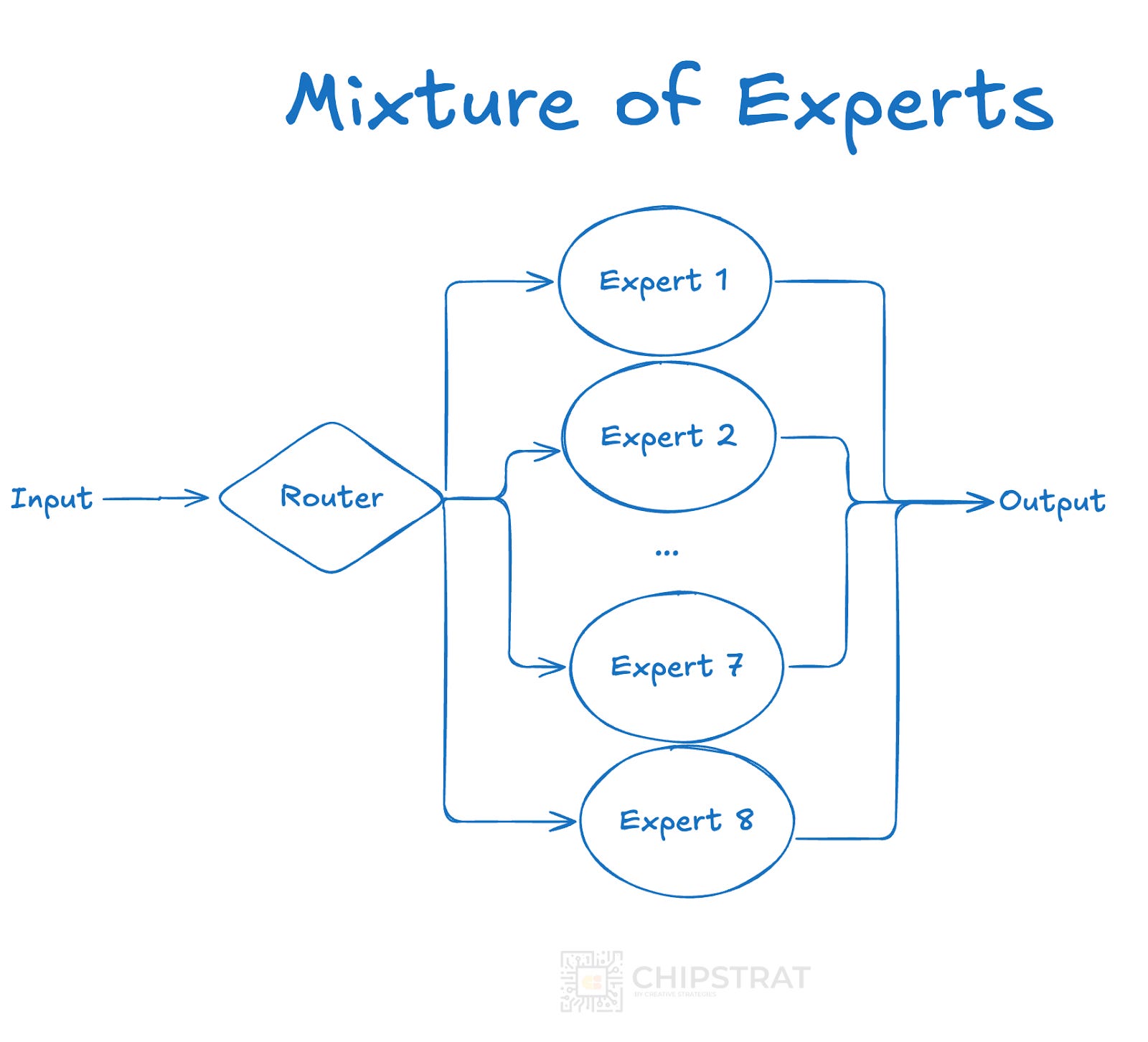
Again, the key insight: for each token in each layer, only two of the experts are “lit up” while the rest stay dormant:
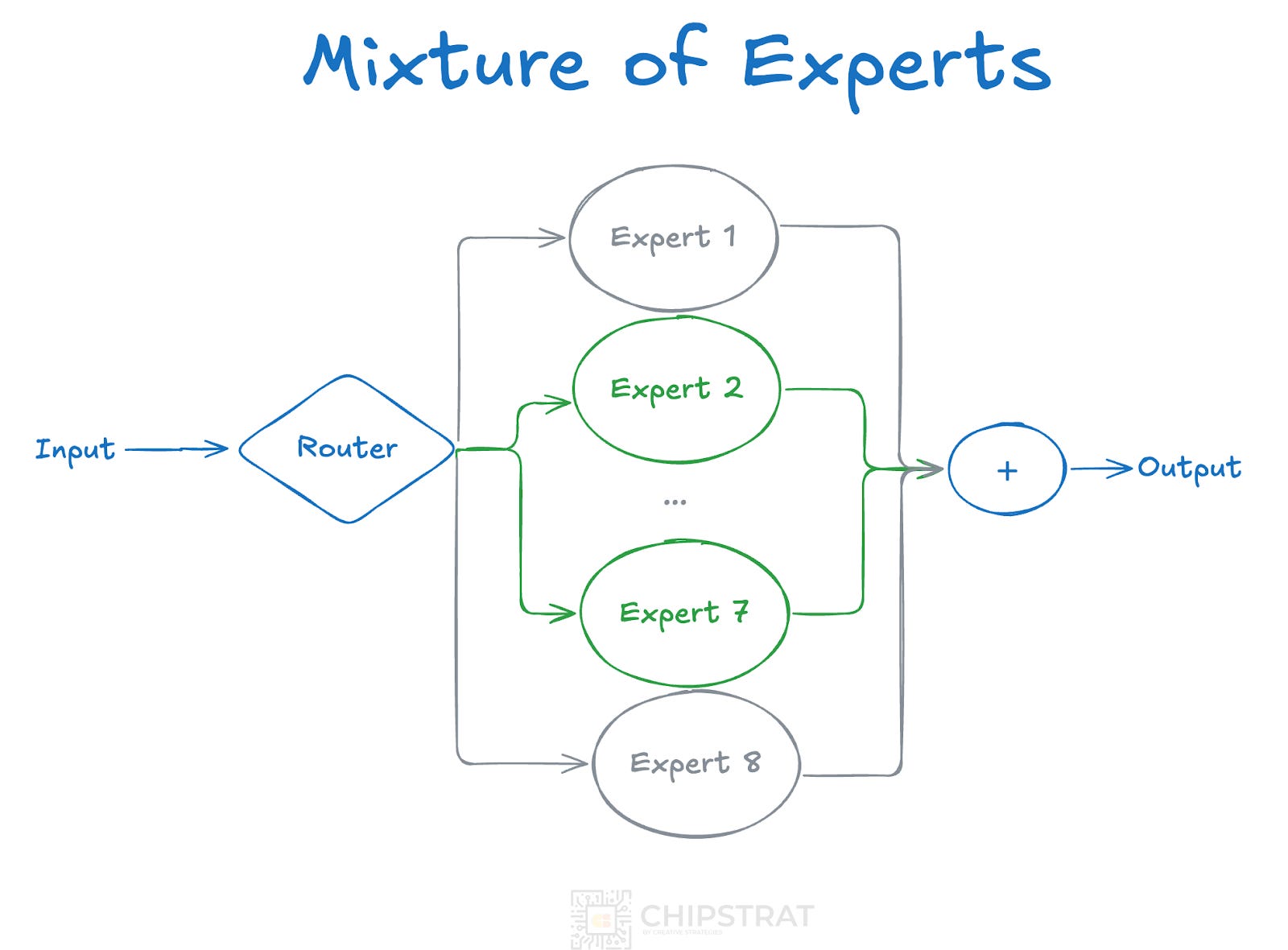
Some terminology: This MoE architecture is sparse, activating only a subset of parameters, unlike traditional dense LLMs that activate all parameters.
The beauty of this architecture is that it provides the intelligence of a 47B parameter model with the computational cost of a 13B model. This sparsity leads to lower latency and higher throughput than a dense model of equivalent intelligence despite the added routing overhead.
These benefits extend to training as well. Since training involves a forward pass (identical to inference) followed by gradient descent and backpropagation, the forward pass selects two experts, and the backward pass only updates those same two. In Mixtral's case, gradients only flow through the 13B active parameters. This makes training much more computationally efficient than training a dense model of the same overall size, even with some overhead like training the router networks that decide which experts to activate and load balancing experts during training to prevent some experts from being underutilized.
Surprisingly, Mixtral's launch didn't cause alarm about AI accelerator demand.
So, back to DeepSeek V2 paper, which notes
… DeepSeek-V2, a strong open-source Mixture-of-Experts (MoE) language model, characterized by economical training and efficient inference through an innovative Transformer architecture.
DeepSeek MoE
DeepSeek V2 employs the DeepSeek Mixture of Experts architecture, introduced in their January 2024 paper, "DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models."
Side note: Man, these guys have been cranking out good stuff for some time now! Sort of that “overnight success several years in the making”.
Traditional MoE architectures, like Mixtral's, suffer from redundant expert knowledge. DeepSeek's innovation lies in recognizing that increased expert specialization allows for fewer active parameters per expert by minimizing knowledge overlap.
So DeepSeek MoE paper introduced two key strategies: fine-grained expert segmentation and shared expert isolation.
Fine-Grained Expert Segmentation
This approach enhances specialization by dividing experts into smaller, more focused units, each learning distinct, non-overlapping knowledge. This reduces redundancy and allows for smaller active parameter sizes. Furthermore, these finer-grained experts enable more precise combinations, leading to improved accuracy.
Shared Expert Isolation
DeepSeek explains this one well:
Shared Expert Isolation: we isolate certain experts to serve as shared experts that are always activated, aiming at capturing and consolidating common knowledge across varying contexts. Through compressing common knowledge into these shared experts, redundancy among other routed experts will be mitigated.
By centralizing shared information among these experts, other experts can focus on specialized tasks without duplicating general knowledge. Maybe this is sort of another way at looking at specialization? Hey guys, I’ll take the easy general trivia questions. Bobby, you’re our sports guy. Jill, you take science questions.
DeepSeek’s improved specialization results in a significantly lower ratio of active to total parameters while maintaining strong performance.
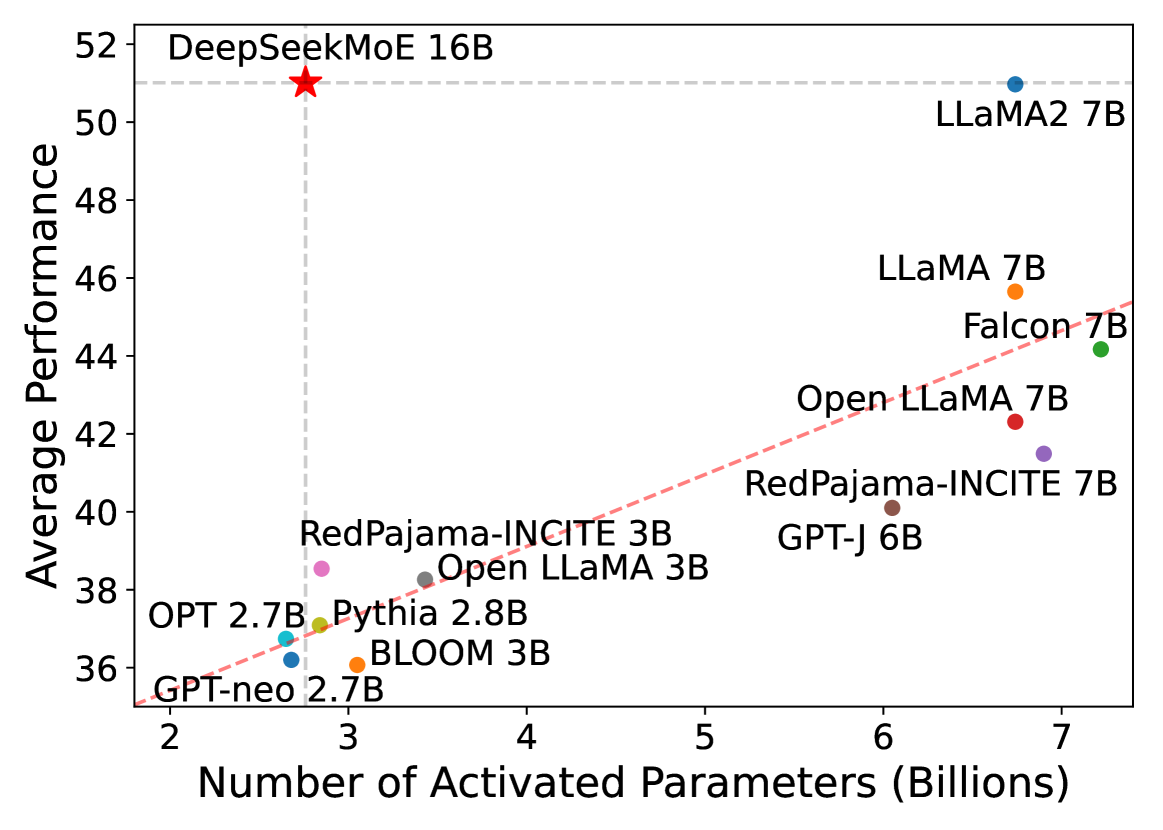
DeepSeekMoE demonstrates remarkable efficiency. Despite having 16.4B total parameters, it only activates 2.8B (roughly 18%) per token. By the way, this MoE paper dropped only a few days after Mistral’s but showed much better active expert efficiency.
This DeepSeek MoE paper shines the first light on DeepSeek’s accelerator infrastructure
All experiments are carried out on clusters equipped with NVIDIA A100 or H800 GPUs. Each node in the A100 cluster contains 8 GPUs connected pairwise via the NVLink bridge. The H800 cluster also features 8 GPUs per node, interconnected using NVLink and NVSwitch within nodes. For both A100 and H800 clusters, InfiniBand interconnects are utilized to facilitate communication across nodes.
The H800, a Hopper-based chip, features reduced communication bandwidth due to export restrictions, including a halved NVLink C2C speed.
DeepSeek V2
V2 used the DeepSeekMoE architecture with a new Multi-head Latent Attention mechanism, and new compute and communication optimizations.
Multi-Head Latent Attention
Without getting too into the weeds, the V2 paper introduces an innovative self-attention architecture called Multi-Head Latent Attention (MLA). Traditional Multi-Head Attention (MHA) requires storing full key-value (KV) caches for every token, which scales poorly as the context window grows.
DeepSeek’s MLA does some voodoo matrix math (“low-rank joint compression” and “decoupled rotary position embedding”) to reduce KV cache memory requirements by 93% compared to MHA.
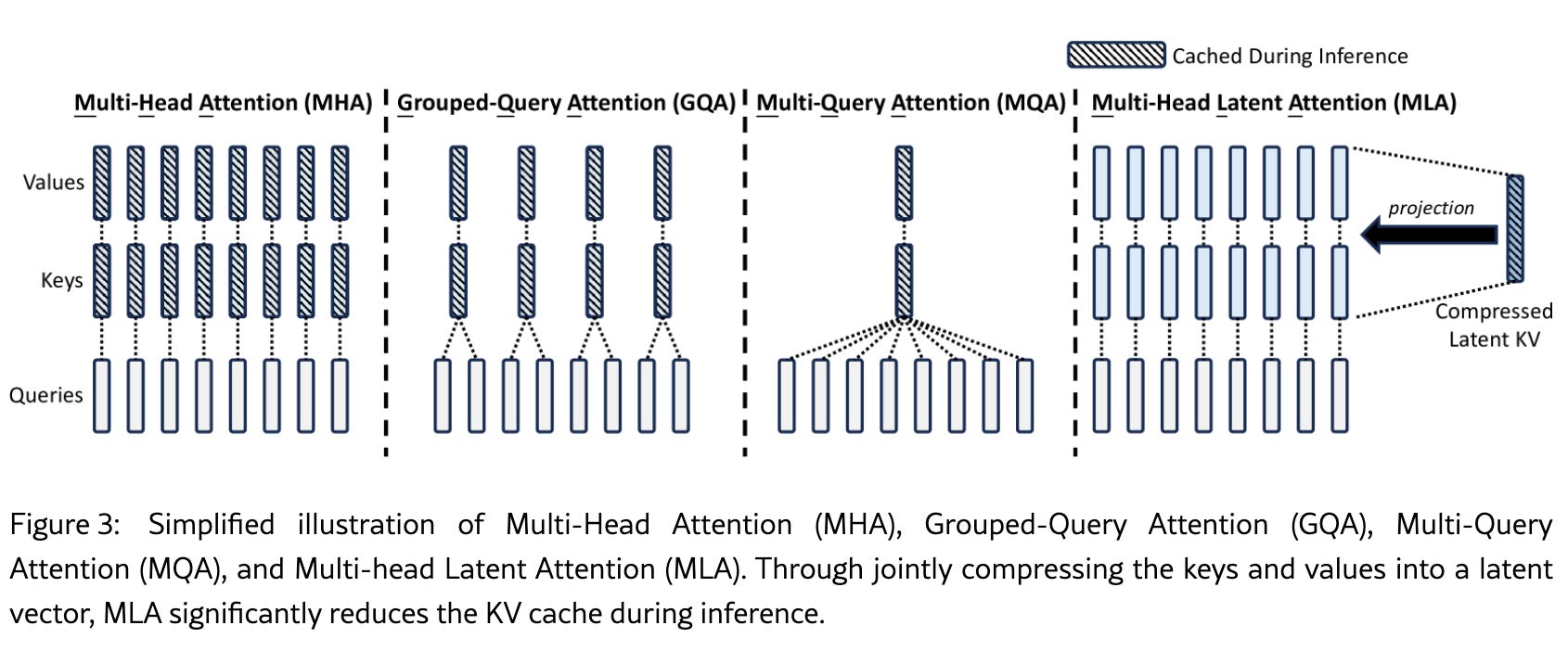
This allows for much longer context windows without a prohibitive memory cost.
Long Context Window
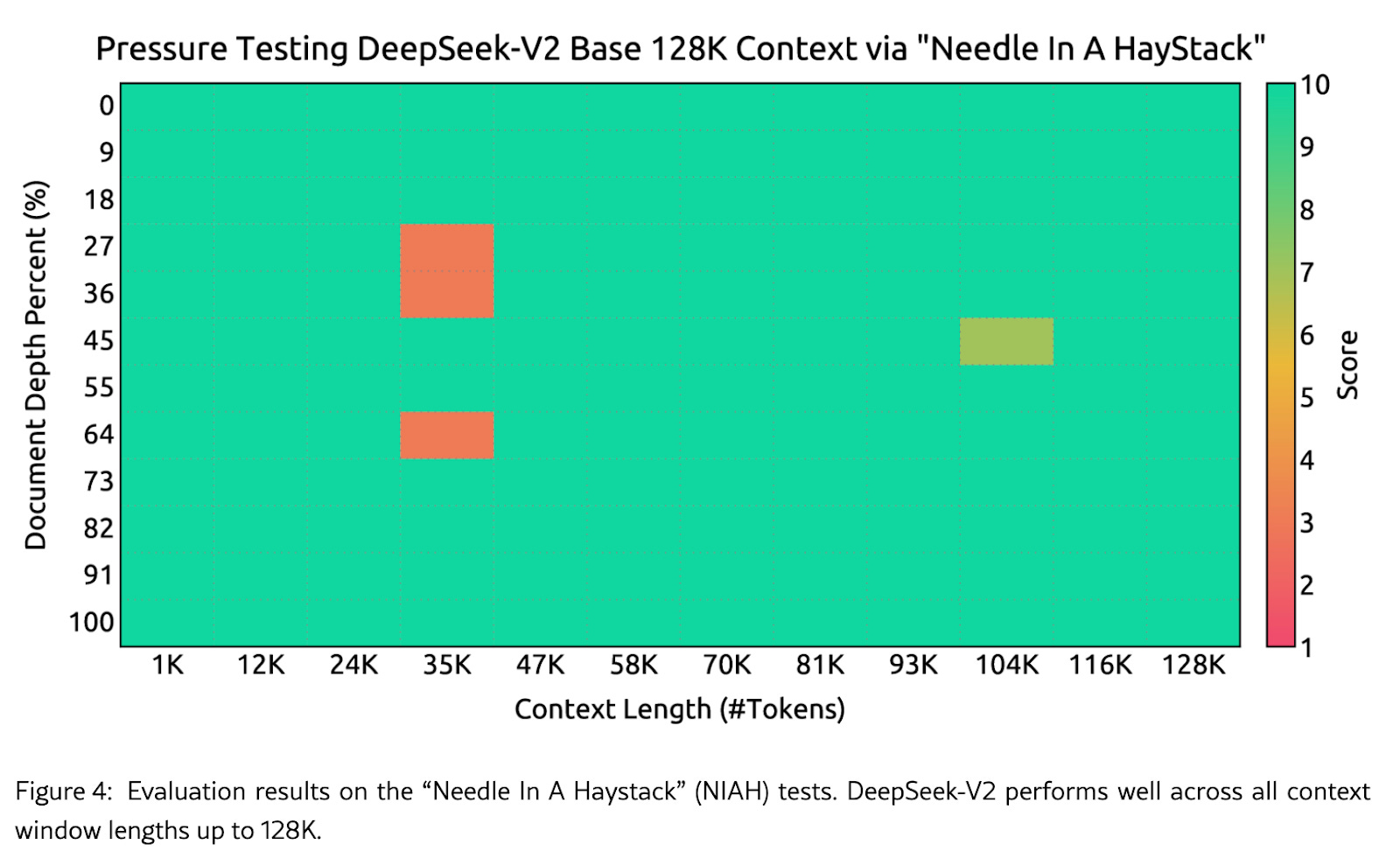
MLA enables a significantly expanded context window, increasing it from 4K up to 128K tokens. This helps the model to "remember" and process significantly more text—roughly 100,000 words, or about the length of a Harry Potter book.
The fun way of testing this is feeding in long inputs (like said book) and asking very specific questions about something buried in the book—a “needle in a haystack” test.
Optimizations
Necessity is the mother of invention. Remember the nerfed H800s they are using?
MoE architectures distribute computation across GPUs, but communication bandwidth can be a bottleneck, especially with H800s. To reduce the communication overhead while maintaining performance, DeepSeek V2 introduced a bunch of clever optimizations that balance the workload and reduce the amount of communication.
For details, see the paper’s discussions of Device-Limited Routing, Load Balancing Losses, and a Token-Dropping Strategy.
There’s also mention of compute optimizations too.
We also customize faster CUDA kernels for communications, routing algorithms, and fused linear computations across different experts. In addition, MLA is also optimized based on an improved version of FlashAttention-2 (Dao, 2023).
Efficient communication and computation translate to higher Model FLOP Utilization (MFU).
Although training an MoE model will introduce additional communication overheads, through our operator and communication optimizations, the training for DeepSeek-V2 can attain a relatively high Model FLOPs Utilization (MFU)
MFU
MFU is a measure of system efficiency, as introduced by Google back in 2022. It’s essentially a ratio of the observed throughput (tokens-per-second) to the theoretical maximum throughput.
We propose a new metric for efficiency that is implementation-independent and permits a cleaner comparison of system efficiency, called model FLOPs utilization (MFU). This is the ratio of the observed throughput (tokens-per-second) relative to the theoretical maximum throughput of a system operating at peak FLOPs. Crucially, the “theoretical maximum” throughput only accounts for the required operations to compute the forward+backward passes, and not rematerialization. MFU therefore allows fair comparisons between training runs on different systems, as the numerator is simply the observed tokens-per-second, and the denominator is only dependent on the model architecture and published maximum FLOPs for a given system.
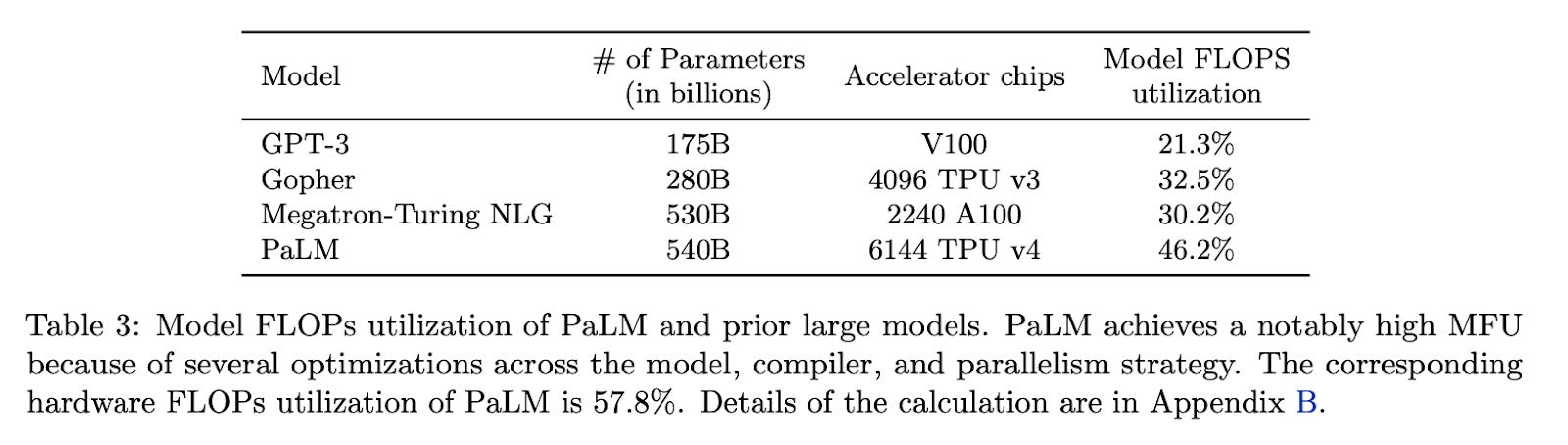
DeepSeek didn’t publish their MFU; they simply state that their optimizations allow them to wring more throughput out of their system.
It's encouraging to see efficiency improvements. The pretraining scaling race often pushes companies to acquire vast numbers of GPUs with limited regard for actual utilization (MFU). With billions spent on hardware, seeing only 30-40% performance utilization is frankly a bit disheartening. Any gains in maximizing our existing infrastructure are highly welcome.
V2 Efficiency
Training
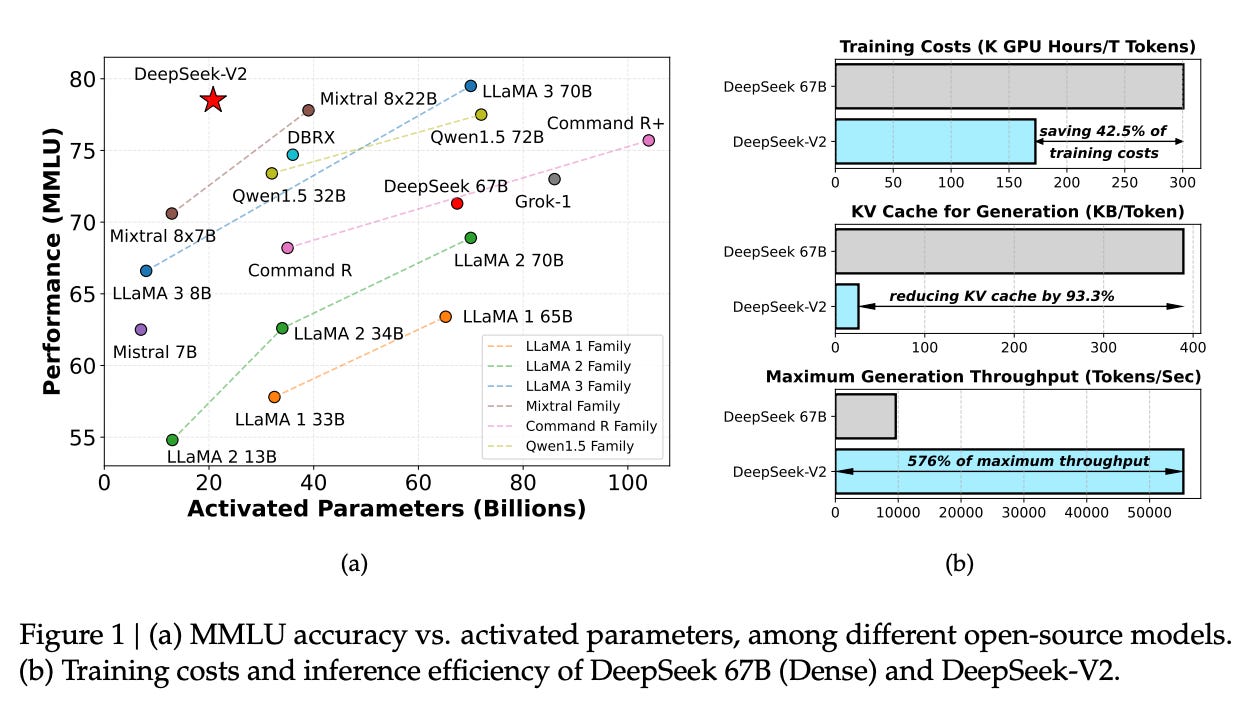
DeepSeek V2's combination of MoE, MLA, and communication optimizations significantly improves training and inference efficiency compared to their dense 67B model:
During our practical training on the H800 cluster, for training on each trillion tokens, DeepSeek 67B requires 300.6K GPU hours, while DeepSeek-V2 needs only 172.8K GPU hours, i.e., sparse DeepSeek-V2 can save 42.5% training costs compared with dense DeepSeek 67B.
This reduction in GPU hours translates to faster iteration speeds—great for R&D innovation.
Inference
Inference optimizations, including FP8 precision conversion and KV cache quantization (averaging 6-bit precision), further reduce memory and compute requirements, leading to larger batch sizes and significantly improved throughput.
On a single node with 8 H800 GPUs, DeepSeek-V2 achieves a generation throughput exceeding 50K tokens per second, which is 5.76 times the maximum generation throughput of DeepSeek 67B. In addition, the prompt input throughput of DeepSeek-V2 exceeds 100K tokens per second.
V2 Summary
Whew! This V2 paper packs a punch. A quick recap:
Efficient MoE Architecture – Uses only a fraction of the network per token (9%), thanks to expert segmentation and shared experts.
Multi-Head Latent Attention – Reduces KV cache size by 93% and enables a 128K context window
Communication & Compute Optimizations – Implements load balancing and custom CUDA kernels to improve efficiency and reduce bottlenecks.
Training Efficiency – Processes 4× more tokens than DeepSeek 67B while using 40% fewer GPU hours
Inference Efficiency – Achieves ~5.8× higher throughput than DeepSeek 67B on 8 H800 GPUs, powered by FP8 precision and KV cache quantization.
Also, DeepSeek's papers often leave breadcrumbs hinting at future directions. This paper, for example, laid the groundwork for their R1 reasoning model:
Then, we collect 1.5M conversational sessions, which encompass various domains such as math, code, writing, reasoning, safety, and more, to perform Supervised Fine-Tuning (SFT) for DeepSeek-V2 Chat (SFT). Finally, we follow DeepSeekMath (Shao et al., 2024) to employ Group Relative Policy Optimization (GRPO) to further align the model with human preference and produce DeepSeek-V2 Chat (RL).
Conversational data, SFT, RL, and GRPO… sound familiar?
Implications
Behind the paywall, we’ll analyze the implications of DeepSeek V2's innovations on
Training compute demand
Inference compute demand
Chinese AI lab business models
American AI lab business models
Open source competitors