

FPGAs - Speed of Hardware, Flexibility of Software
Deep-dive on FPGAs - Basics, Economics, Trade-offs, AI & LLMs

GPUs are all the rage, but have you ever given a second thought to FPGAs? No? Well, I can't blame you. They're a bit of an acquired taste. But let’s explore them together and see if they have a role to play in this GenAI world.
We’ll start in the shallow end to get everyone comfortable then venture into deeper technical waters, culminating in LLMs on FPGAs. Technical folks, feel free to jump ahead for the advanced stuff!
If you’re a “strategy of semiconductor business” thinker, my next post will dive back into familiar analysis waters so stay tuned (but also read this one!)
New subscribers - welcome! If you’ve never been in these parts before, I’m building a backlog of foundational semiconductor posts to ensure all subscribers have just enough technical depth to truly understand the industry. I touch on the how and strongly emphasize the why behind the technology. Here are fundamentals of CPUs, GPUs, and ASICs to help you acclimate: Chipstrat - Fundamentals
FPGA Basics

It’s now time to study the most common reconfigurable computing logic chip – the FPGA. The acronym stands for Field-Programmable Gate Array, but never mind that for now.
FPGAs are reprogrammable hardware. Unlike CPUs or GPUs, which rely on executing software instructions, FPGAs can be directly rewired at the circuit level.
FPGAs combine the speed of hardware with the flexibility of software. This allows users to create highly specialized hardware tailored to their exact application, often resulting in significant speed and power efficiency advantages.
📖 Field Programmable Gate Array (FPGA) - An FPGA is a configurable chip that can be reprogrammed after manufacturing
💡FPGAs offer hardware-like speeds with software-like flexibility
Building Blocks of FPGAs
Conceptually, an FPGA consists of a multitude of simple configurable building blocks and wires for connecting them however you like.
The building blocks are called configurable logic blocks (CLBs). Think of them as a box with a circuit inside that can take input values and return an output value. The power of these CLBs is that you can tune the circuit inside of them to return particular output values for given inputs. As an illustration, you could make a CLB compute an arbitrary math function like y = x2.

The amazing thing about these simple logic blocks is that you can configure and combine them to build increasingly complex circuits. For example, a relatively small number of blocks can be wired together to build simple control circuits like those to control an elevator or a vending machine. It’s quite simple in an elegant way.
🤔 A quick aside: If you're curious about the process of creating digital circuits from basic elements, regardless of technical expertise, I highly recommend checking out a “Digital Logic” course or book. Don't be put off by terms like Boolean logic and finite state machines — they're just precise, if rather uninspiring, labels.
This focus on technical precision over accessibility is a common issue in the semiconductor industry, making it seem more complex than it needs to be. We could at least copy the scientific world and have both a precise technical name for our pedantic friends and a memorable name for the rest of us. For example, the prairie grass known as Little Bluestem has the technical name Schizachyrium scoparium. Let’s stick with Little Bluestem, shall we?

Maybe we need to fine tune a “Marketing Copilot for Engineers” AI model to help the semiconductor industry and academics with creative naming 😎
How FPGAs Work
How does one configure and combine these simple logic blocks to implement their desired functionality? FPGAs can be “programmed” using a hardware description language (HDL) that describes how the circuit should behave.
📖 Hardware Description Language - a programming language used to describe digital circuits
FPGA manufacturers make software (Xilinx Vivado, Altera Quartus, etc) that translates HDL code into a set of instructions called a bitstream. FPGAs have specific memory for storing a configuration bitstream that, when loaded, dictates how the device's logic blocks should be configured and interconnected, thus customizing the FPGA into a unique hardware accelerator according to the design requirements. This direct hardware implementation makes FPGAs efficient for specific, repetitive tasks.
One quick analogy to help solidify the concepts and then we’ll move onto the benefits of FPGAs.
Reconfigurable City Planning
As an analogy, imagine an FPGA as a blank city grid waiting to be developed. This landscape consists of a grid of streets, stoplights, and empty lots. As the city planner it’s up to you to create the blueprint that determines where factories, warehouses, office buildings, and so on are constructed. You can then program the traffic control system to ensure an optimized flow of traffic to various points in the city at certain times of day. You can combine buildings and traffic flow to produce valuable outputs. For example, you could bring materials into a factory and have finished goods leave the factory and travel to a department store. It’s totally up to you given the outcome you’re trying to achieve.
In this analogy, the empty lots represent logic blocks that can be built upon to implement desired functionality. The city streets represent wiring between logic blocks for data to flow to and from the various functional units. The city planner’s blueprint is analogous to the FPGA programmer’s HDL code that describes what functionality should be built upon each logic block. This blueprint also conceptually contains the traffic control system instructions to manage the flow of data to and from the logic blocks.
The amazing thing about FPGAs is that they can be reconfigured in a matter of seconds by simply loading new HDL code. Have an idea how to make the system more efficient? Or an idea for a new feature? Just reprogram it!
This would be like giving the city a new blueprint: buildings can change purpose and the traffic control system can be modified. Wouldn’t that be awesome? Like – hey, our city wants to encourage pedestrians to travel to work by bike, let’s invest in bike paths through downtown and we’ll reconfigure the roads and stop lights accordingly.

Primary Benefits of FPGAs

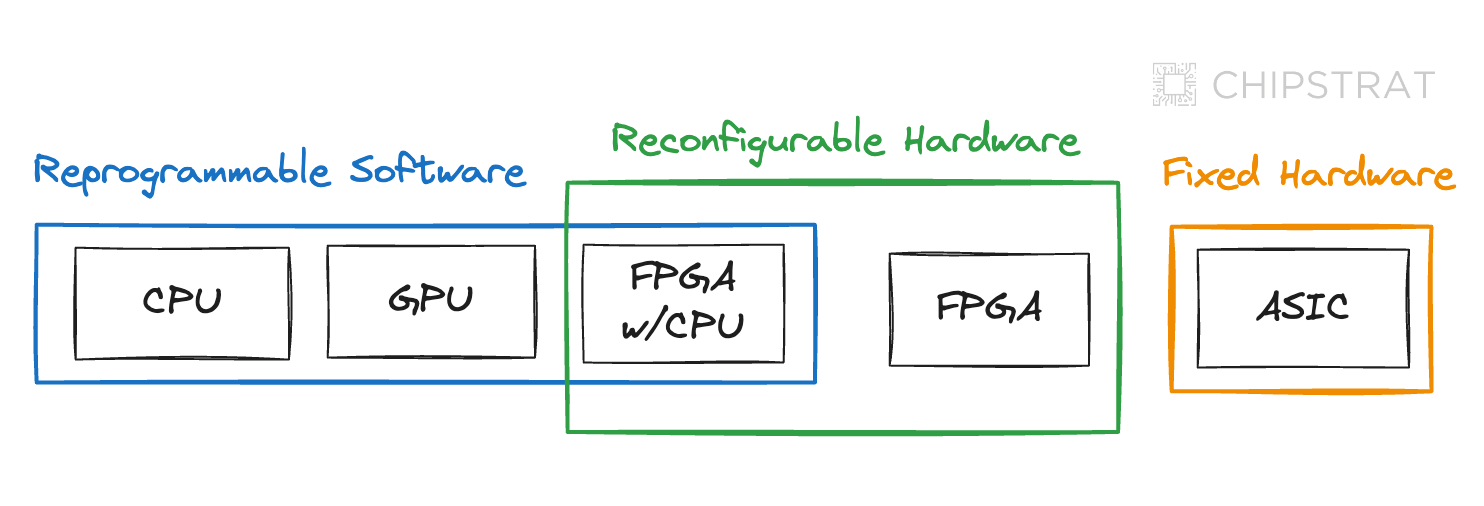
As we discuss the benefits of FPGAs, it’s helpful to remember that FPGAs conceptually sit on a spectrum between general-purpose CPUs/GPUs and purpose-built ASICs for a variety of dimensions including latency, power efficiency, and flexibility. As such, let’s first look at the benefits of FPGAs as compared to ASICs, then compared to CPUs/GPUs.
💡FPGAs occupy a middle ground in the flexibility, performance, and power trade-off spectrum, sitting between general-purpose chips and fully custom ASICs.
FPGAs are a powerful tool, and like many things in engineering the best answer to whether they're the right fit is often the consultant’s classic answer – ”it depends”.
FPGAs vs ASICs
Benefits
Both FPGAs and ASICs deliver latency and power efficiency gains compared to CPUs and GPUs, but FPGAs offer reconfigurability, lower development costs, and a shorter path from design to deployment compared to ASICs.
ASICs are unalterable, but FPGAs can have their internal circuitry reprogrammed to perform different tasks. This allows for updates, bug fixes, and even the implementation of completely new features while the chip is in the field! This ability to adapt and evolve extends a product's lifespan and makes FPGAs a compelling choice for situations where requirements might change or long-term adaptability is important.
It also enables customization during manufacturing for companies seeking to provide customers with flexible product options. Instead of designing and manufacturing a wide range of boards with slight variations, a single base board with an FPGA can be used. The FPGA's internal circuitry can then be customized through programming during the manufacturing process, adapting the board's functionality to specific customer requirements.
💡FPGAs can be reprogrammed after deployment, enabling updates, bug fixes, and new features.
Development Cost and Time to Market
Understanding the differences between FPGA and ASIC development helps explain why upfront costs and time-to-market vary so significantly.
Both development processes start similarly by using software (HDL) to describe the circuit's function. FPGA development basically ends there – load the HDL onto silicon, validate it works, and go!
ASICs, on the other hand, require a much longer and more complex process of translating the functional description into an actual circuit of transistors. This involves translating the software description of the circuit into a physical silicon layout that specifies the quantity, placement, and interconnection of transistors on the chip. This step also includes incorporating test circuitry to facilitate post-manufacture testing of the chip. Following this, extensive simulated testing is conducted to ensure that the circuit, now translated into a physical form, behaves as expected, with particular attention to data flow, timing, and any potential negative ramifications arising from the physical layout.
Then the long process of ACTUALLY MAKING THE CHIP, which typically is done by a different company that specializes in semiconductor fabrication called a foundry. The process starts with sand (silicon), then a bunch of science happens, and out pops a computer chip that can stream your favorite music on Spotify. 🤯🤯🤯

Here’s a simplistic conceptual diagram to illustrate that ASICs and FPGAs both start with HDL to describe and simulate the circuit, but ASICs then have a lengthy process to turn the software into a manufactured chip.

The first step is sometimes referred to as front-end design, and the design phase of the second step is referred to as back-end design.
Back-end design involves many steps to convert the HDL description into a blueprint for a semiconductor foundry, which I’ll call “physical design” for simplicity.
Likewise, the foundry has many steps for fabrication, we’ll skip the details and call that “fabrication”.
Just know that there are many steps inside both of these workflows and they can take a significant amount of time and expense. A simple illustration is as follows:

💡Both FPGAs and ASICs use software to define their circuitry. ASICs have additional steps — translating that software design into a physical chip layout followed by the entire manufacturing process.
Understanding the differences between FPGA and ASIC development makes the advantages of FPGAs quite clear.
The lower initial development cost and quicker time-to-market of FPGAs stems from their reliance solely on front-end design.
In contrast, ASIC development’s back-end design requires specialized knowledge and incurs additional expenses, for example Electronic Design Automation (EDA) tool licenses. ASICs then have additional foundry fabrication costs.
This long and expensive ASIC development process amplifies the cost implications of errors. Discovering a bug in an ASIC after manufacturing presents a dilemma: either accept the flaw or face a costly and time-consuming redesign and fabrication process for a chip “respin”. This reminds me of the predicament faced by previous generations of college students who used typewriters (hi Mom!) – finding an error meant retyping the entire page or leaving it alone and dealing with the consequences.
Economics
The economics of FPGAs vs ASICs are commonly conceptualized in a chart like this:

This presentation simplifies the FPGA vs. ASIC decision using a cost curve analysis familiar from Econ 101.
ASICs have high initial investment (the y-intercept) but minimal per-unit costs (the gradual slope). FPGAs invert this model, with lower upfront costs but higher expenses per unit produced. Let’s explore this a bit more.
ASICs demand substantial upfront investment in design and manufacturing (non-recurring engineering costs). However, they offer much lower per-unit production costs due to their application-specific optimization.
Why the higher per-unit cost for FPGAs? Their reconfigurable design, including configurable logic blocks and flexible routing, requires more transistors and silicon area. This flexibility comes at a cost compared to purpose-built ASICs.
Thus, for prototyping or smaller production runs, the lower upfront costs of FPGAs often outweigh their higher incremental costs. But in high-volume production scenarios, ASICs become more cost-effective as the substantial initial investment is spread out over a large number of units, taking advantage of economies of scale.
More Than Econonomics
The choice between FPGAs and ASICs may seem straightforward at first glance – simply estimate the production volume, calculate the crossover point, and decide accordingly. However, the decision must also factor in the "opportunity cost," often framed as "time-to-market." By opting for a shorter development cycle, let's say six months instead of eighteen, one avoids missing out on opportunities for iteration or pivoting during those additional twelve months.
Moreover, if there is uncertainty about achieving product-market fit, it might be wise to run with FPGA prototypes initially. This approach allows front-end design and postponing back-end work until validating the market demand and refining the product based on user insights. Gathering early feedback from customers before committing to an ASIC design can be invaluable before finalizing a more rigid and costly ASIC implementation.
Ultimately, the decision between FPGAs and ASICs hinges on carefully weighing the trade-offs between flexibility, time-to-market, development costs, and production volumes. FPGAs excel in scenarios where requirements are fluid, rapid prototyping is crucial, and upfront costs need to be minimized. Their reconfigurability allows for bug fixes, feature enhancements, and even pivots in functionality post-deployment. However, for high-volume production runs with stable requirements, ASICs become the more economical choice due to their optimized performance and lower per-unit costs despite substantial upfront investments. By factoring in opportunity costs, potential product-market fit risks, and the projected scale of production, companies can strategically navigate the FPGA-ASIC decision to align their hardware implementation with their specific business goals and broader market dynamics.
💡When choosing between an FPGA and an ASIC, the economics are driven by volume, but decision makers must also weigh opportunity costs and the need for flexibility.
FPGAs vs. CPUs/GPUs
Performance vs. Ease of Use
Now let’s compare FPGAs with general-purpose logic chips like CPUs and GPUs.
FPGAs are well-suited for implementing parallel algorithms and can exploit both data parallelism (dividing data amongst replicated processing units) and task parallelism (distributing different parts of an algorithm across multiple processing units).
Like ASICs, implementing a custom circuit on an FPGA strips out the bloat (overhead of instructions and control logic found in general-purpose processors), which results in lower latency and higher power efficiency.
However, FPGA programming has a reputation for being difficult.
FPGAs are programmed using HDLs like Verilog or VHDL, which operate at a lower level of abstraction than traditional software programming languages, requiring developers to think in terms of parallel logic and hardware resources. This complexity can make it challenging to find and hire skilled FPGA programmers. In contrast, CPUs and GPUs are easier to program using high-level languages like C++ or Python with a larger pool of available developers.
Unlike the FPGA vs. ASIC decision, where both paths demand HDL skills, a team facing the FPGA vs. GPU choice might lack FPGA expertise. In this case where a team lacks HDL skills, prototyping on a GPU can be a practical solution for customer validation while the team determines if the GPU's performance suffices in the long term.
Alternatively, the team could reach for tools enabling FPGA programming using more familiar levels of abstraction.
For example, AMD Vitis HLS (High-Level Synthesis) allows developers to code in familiar languages like C++ and then translates this code into HDL for the FPGA. This is a viable path for prototyping on FPGAs without having an HDL engineer on the team. However, there's still a learning curve associated with understanding how to write code that synthesizes effectively into HDL. Additionally, like any software translation process, automatically generated code is often less efficient than hand-optimized code written directly in HDL. That said, if the goal is to get a prototype into customers hands quickly to learn and iterate, this is a great path, as performance optimization can always come later.
🤔 As an aside: Our industry desperately needs an "HDL Copilot" powered by an LLM to assist developers with HDL code generation, suggestions, and best practices. In the long run, this could significantly lower the learning curve and reduce overall HDL development costs, materially impacting FPGA adoption!
FPGA manufacturers and/or their customers could use their vast repositories of HDL code to create this "GitHub Copilot for Hardware". Yes, there would be concerns about such a model leaking proprietary code, but surely the industry could figure out workable solutions.

Costs
The cost of FPGAs versus CPUs and GPUs varies widely across different performance tiers. Generally, FPGAs tend to be more expensive per unit due to lower production volumes, lack of the same economies of scale as mass-market CPUs/GPUs, and the additional silicon complexity needed for their reconfigurable nature. However, like CPUs and GPUs, FPGAs offer a range from cost-sensitive options to high-performance flagships. While mainstream CPUs/GPUs often achieve very low per-unit pricing, high-end datacenter GPUs like NVIDIA's H100 can command premium pricing on par with high-performance FPGAs. The cost-optimal solution ultimately depends on specific workload requirements, performance targets, and expected production volumes.
Deciding between FGPAs and CPU/GPU
The decision between FPGAs and CPUs/GPUs comes down to this: FPGAs offer the best performance and power efficiency for specific tasks, but are harder to program. CPUs and GPUs are easier to use and have a larger pool of developers, but may sacrifice efficiency. Tools like HLS can make FPGAs more accessible, and the potential for an "HDL Copilot" could change the equation further. Ultimately, the ideal choice is determined by the specific performance needs of the application, the expertise of the development team, and the projected production volume.
💡Choose CPUs/GPUs when development speed and a large talent pool are critical, and choose FPGAs when maximizing performance and power efficiency outweighs development complexity.
IP Blocks: The Building Blocks of FPGA Design
What are IP Blocks?
FPGA development can be sped up by reusing existing code, called Intellectual Property (IP) blocks. IP blocks in the semiconductor industry act like standardized parts used in home construction. Just as a builder utilizes prefabricated doors, windows, and shingles to expedite the building process, chip designers use pre-made and pre-tested circuit components to efficiently assemble chips. IP blocks allow engineers to concentrate on differentiating features. While there are licensing costs associated with IP blocks, the benefits in time savings, risk reduction, and potential performance improvements often justify the investment.
📖 Intellectual Property (IP) Blocks - pre-designed, reusable circuit components (often licensed from third parties) that perform specific functions within a larger chip design
Soft IP vs. Hard IP
Soft IP cores, delivered as synthesizable Verilog or VHDL code, can be used in both FPGAs and ASIC design. On an FPGA, the IP core maps to the device's reconfigurable logic blocks and routing. Pre-configured blocks delivered as HDL code offer the chip designer the flexibility of customizing the block per the larger design’s needs.
📖 Soft IP - pre-designed functional blocks of a chip delivered as source code
Hard IP refers to pre-designed and optimized circuits embedded directly into the FPGA's silicon. They use up chip area but don't consume any of the FPGA's reconfigurable logic resources.
📖 Hard IP - pre-designed optimized circuits on the FPGA chip that don’t use reconfigurable logic
It’s easiest to see the difference between Soft and Hard IP with a simple illustration:
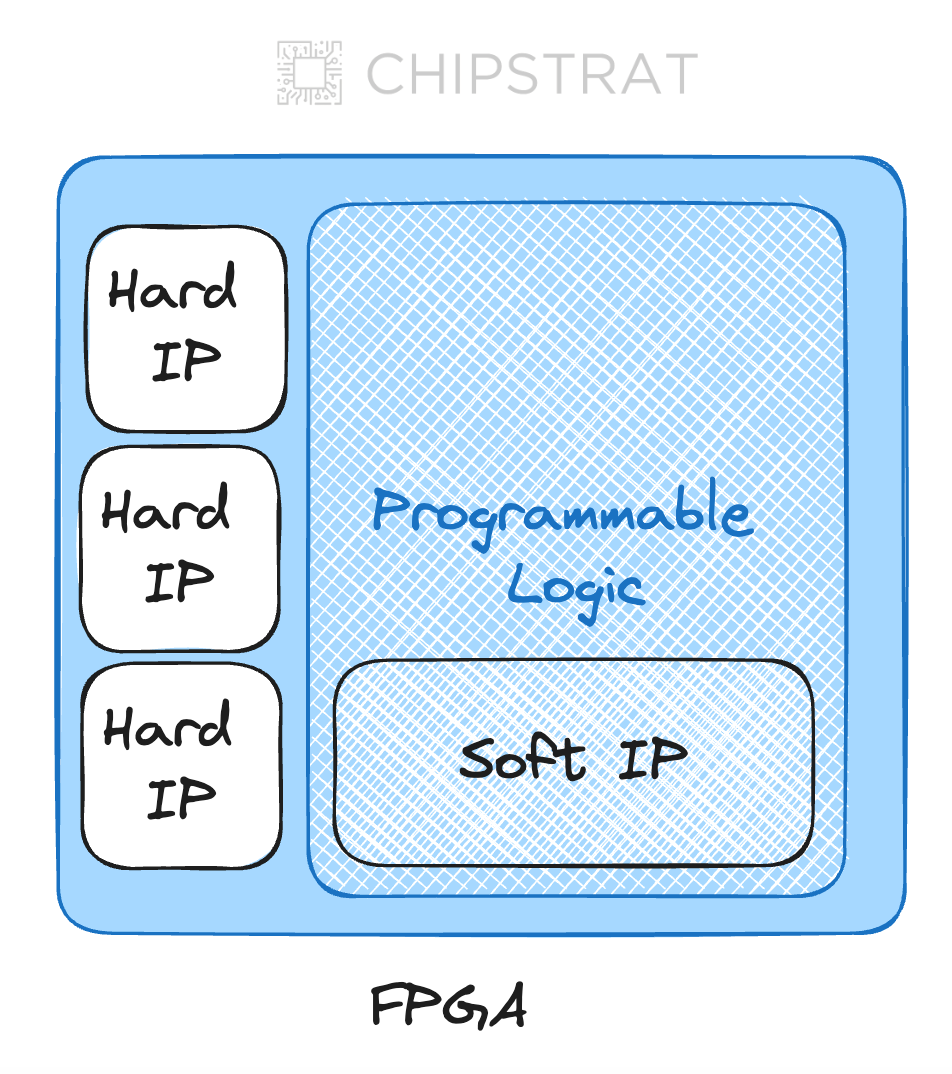
As an example of hard IP, many FPGAs include dedicated hard IP blocks for common communication protocols like Ethernet or PCIe. These blocks offer superior performance and power efficiency compared to implementing the same protocols using the FPGA's reconfigurable logic. This conserves valuable reconfigurable fabric for truly custom, low-latency, and power-sensitive domain-specific applications.
FPGA SoCs: The Best of Both Worlds
The lines are blurring!
IP cores make it easier to add processors to FPGAs, giving them the ability to handle both custom hardware tasks and general-purpose software.
Think of this like a CPU with a custom accelerator – the FPGA tackles demanding workloads while the CPU handles routine operations like networking, user interactions, and so on. This can simplify development, allowing developers familiar methods for the CPU-side software.
These often are referred to as an FPGA System-on-a-Chip (SoC).
We haven’t built our way up to SoCs yet on Chipstrat, so a quick definition:
📖 System-on-a-chip - a circuit that integrates components of a system into the same piece of silicon
FPGA SoC is quite a clunky name. AMD calls them “adaptive SoC”, which I dig! Not sure if they invented this term or just embrace it, but either way it’s great. Let’s use this in our training set when fine-tuning our “Marketing Copilot for Engineers” model 😎

💡An FPGA SoC delivers the best of both worlds: customizable hardware for demanding tasks alongside a familiar CPU for general software, boosting performance and development efficiency.
Example: Advanced Driver-Assistance Systems
Let’s put it all together with an Advanced Driver Assistance Systems (ADAS) example.
An automaker might use an adaptive FPGA to implement ADAS features. This setup takes advantage of the FPGA's ability to process images with low latency, supporting ADAS functionalities such as lane departure warnings, pedestrian detection, and adaptive cruise control. The CPU, on the other hand, manages decision-making, system management, communications, and user interaction.
For example, in a lane departure warning system, the FPGA could initially capture images from cameras, apply preprocessing to reduce noise and detect edges, and finally run lane detection algorithms. These processed images and lane information would be forwarded to the CPU, which would assess the vehicle's position within the lane and carry out more complex tasks like generating alerts or initiating corrective measures.
Using a combination of a hard IP CPU and an FPGA allows for an efficient distribution of tasks, optimizing the strengths of each processor: the CPU handles control tasks and system adaptability, while the FPGA focuses on low-latency processing. This arrangement not only ensures rapid responses crucial for ADAS safety but also accommodates future enhancements in ADAS technologies and algorithm updates.
Note that the automobile with this SoC FPGA may be in use for the next decade or longer – reconfigurable FPGA hardware enables automakers to ship over-the-air (OTA) updates to keep up with evolving federal regulations and prevent potential security vulnerabilities.
AI on FPGAs
Edge Inference
As seen in the ADAS example, FPGAs are useful as embedded accelerators given their low latency, high throughput, and energy efficiency. Such a system would likely use a Convolutional Neural Network (CNN) for object detection.
FPGAs are great for CNNs for automotive use cases where low latency and low power consumption are essential. Furthermore, the reconfigurable fabric of FPGAs plus associated hard IP blocks can handle the entire object detection pipeline including pre-processing steps such as image normalization and post-processing such as filtering out low confidence detections.
Beyond CNNs, FPGAs are promising for other edge AI inference use cases that fit within the FPGA’s hardware constraints such as limited on-chip memory capacity and bandwidth. Techniques like quantization, weight pruning, and optimized model parallelism can help mitigate an FPGAs memory limitations. Additionally, FPGA manufacturers are developing AI-specific FPGAs with expanded memory resources.
However, very large ML models like LLMs often remain impractical for FPGAs.
Also, framework support for deep learning on FPGAs lags far behind GPUs. But it does exist and is improving – see AMD’s Vitis AI, which supports running models written with high-level machine learning libraries like PyTorch on Xilinx (AMD) FPGAs.

See this example that compiles a PyTorch model for deployment on an AWS F1 instance, which uses Xilinx FPGAs.
Understanding TOPS/Watt
Because FPGAs can have low-latency AI inference and low energy consumption, FPGA manufacturer’s product marketers will often tout the FGPA’s performance efficiency compared to GPUs and CPUs using a performance-per-Watt metric called TOPS per Watt (TOPS/W).
TOPS (Tera or Trillion Operations Per Second) measures the processing power of AI hardware. It indicates the maximum number of operations (calculations) a device can theoretically perform in one second. However, it's important to note that reported TOPS figures often represent a theoretical maximum or peak performance, not necessarily the sustained performance in real-world applications.
The power consumption required to achieve this peak performance is measured in Watts.
Thus, TOPS/W is “how much peak performance” divided by “how much energy”.
📖 TOPS per Watt - measures how efficiently hardware can perform computations by dividing the device's peak processing power (TOPS) by its power consumption (Watts).
Higher TOPS/W indicates greater efficiency. To improve this metric, competitors can increase peak performance (the numerator) or reduce power consumption (the denominator). Compared to CPUs/GPUs, FPGAs and ASICs with their domain-specific design maximize performance and minimize power.
It's important to take reported TOPS (Tera Operations Per Second) and TOPS/Watt figures for AI hardware with a big grain of salt, as these metrics can be exaggerated by manufacturers.
This exaggeration might occur by using the theoretical maximum performance achievable under optimal conditions for maximum output alongside a theoretical minimum power consumption obtained under different conditions aimed at minimizing energy use. Instead, the performance and power under the same conditions should be reported. Additionally, real-world factors such as hardware underutilization can further diminish the TOPS/W ratio.
Finally, nitty gritty details like model precision and sparsity can significantly inflate performance metrics. For e related example, look no further than Nvidia’s most recent Blackwell launch where they inflate performance metrics between chips by comparing performance with different quantization formats — FP8 precision on the old chip vs FP4 on the new chip, inflating the outcome by 2x.

That said, focusing on the performance-per-watt of AI hardware is important – especially given the escalating power demands of AI and the advantages FPGAs offer in embedded scenarios where power efficiency is paramount.
The key point is that FPGAs can achieve significantly higher performance efficiency than GPUs and CPUs for specific AI workloads – all the while maintaining the reconfigurable benefits discussed above.
LLMs on FPGAs: Opportunities and Challenges
LLMs Can Give Anything A Voice (and Ears!)
Everyone is rightfully excited about the generative nature of transformer LLMs because they give computers the ability to be creative — gamechanging!
That said, a very overlooked AMAZING aspect of LLMs is that they endow systems with the ability to listen and speak! LLMs can listen to you in your native tongue! They can respond in your native tongue! This is revolutionary for human-computer interaction. (I’m obviously excited about this topic!)
We can make anything interactive and open up a world of innovation opportunities by simply embedding a basic speaker, microphone, and LLM into it!
What if the expensive tools used in manufacturing could hold a conversation? This would be so much better than reading a printed manual or calling an expert. Just embed the tool expert into the tool itself! 🤯🤯🤯
The tool is likely reading all sorts of diagnostic data too, so it could hold a data-driven conversation about its health and preventative maintenance like this:
Worker: “Hey tool, something feels off. What's up?”
Tool: “I'm detecting a vibration that's outside normal parameters. I'm also seeing a slight dip in power output. This could be a worn bearing in the motor. Would you like me to run a more detailed diagnostic check?”

Can LLMs Fit on FPGAs?
Given the benefits of FPGAs that we’ve discussed so far, they seem promising for these “give a gadget natural language” use cases that require low-latency and high-throughput to feel natural in conversation, all the while drawing low-power (likely battery operated for most embedded use-cases).
While AI ASICs are another option for low-power, real-time LLM-based natural language processing, FPGAs' reconfigurability enables field updates such as incorporating future advancements in transformer models. Might there be something here?
While promising, researchers are still working through challenges with LLMs on FPGAs stemming from the massive memory requirements for useful LLMs.
For example, from this paper it’s noted that the transformer architecture runs into constraints on FPGAs running LLM inference.
The author suggests a heterogenous system running the prefill stage on GPUs and the decode step on FPGAs, but this isn’t realistic for an embedded scenario. Even in the datacenter, it’s likely simpler and faster-to-market to just run it all on GPUs and accept performance and cost tradeoffs, or run it all on ASICs designed to do both prefill and decode well.
That said, with the rise of chiplet technology, maybe someone like AMD could experiement with adaptive SoCs with hard GPUs and run prefill on the GPUs and decode on the FPGA fabric?
From the customer perspective — it’s unclear from this paper what the actual user experience of the FPGAs running LLaMA2 7B was – was it “good enough”?
I’m assuming the tokens/sec was still fairly low, and that for such embedded systems we’ll likely need further architectural hardware improvements and/or small model innovation to get a “good enough” user experience while keeping costs and power “low enough”.
Conclusion
FPGAs offer a compelling alternative for specific use cases, bridging the gap between the raw performance of custom hardware (ASICs) and the flexibility of software-driven solutions (CPUs/GPUs). Their reconfigurability shines in scenarios where rapid prototyping, lower development costs, and post-deployment updates are crucial. FPGAs excel in power-constrained embedded applications requiring low latency and optimized performance, including certain types of AI inference. However, FPGA programming complexity remains a hurdle. Additionally, challenges exist for running very large AI models such as LLMs directly on FPGAs hardware. As the need for adaptable, high-performance computing grows, FPGAs and adaptive SoCs will likely play an increasingly important role.