



GPU Bloat Stifles AI
Why Jarvis won’t run on GPUs, and how AI silicon startups like Etched can help

Generative AI has no killer app.
Sure, we’ve long had AI-powered features like Netflix recommendations and Facebook feeds, but AI hasn’t transformed human productivity — yet.1
The recent rise of generative AI has ignited optimism that AI’s killer app is on the horizon. Companies are responding by stockpiling GPUs to capitalize on this promise.
Skeptics argue it's a bubble, pointing out that these companies fail to demonstrate how generative AI profitably solves their customer’s problems.
I contend that the primary challenge for generative AI lies not in a scarcity of customer problems or profitable business models, but rather in the latency of AI. Killer apps don’t exist because generative AI is too slow.
Think of video streaming as an analogy. Streaming technology was around in the internet's early days, but slow speeds rendered the experience unusable. A 100x increase in bandwidth was needed to achieve the responsiveness necessary for the development and widespread adoption of video's killer apps such as YouTube, Netflix, Zoom, and TikTok2.
Similarly, generative AI’s killer apps won’t exist until responsiveness improves by at least 10-100x. As with the internet — the faster generative AI gets, the more we will use it.
The limitations of modern LLMs like ChatGPT highlight AI’s latency problem. When asked a question, ChatGPT responds hastily with the impulsiveness of a child. This isn’t the future we dream of (yet so much better than Siri 😂). We want an assistant who analyzes both the near-term and far-reaching consequences of our questions, offering a thoughtful and comprehensive reply. Jarvis, anyone?
Notably, the problem isn’t that today’s LLMs are childlike in knowledge; on the contrary, they encompass deep knowledge across all professions and endless niches. The problem is that modern LLMs aren’t given enough time to think deeply. LLMs unable to intelligently express their embedded knowledge because they think too slowly and it pushes the limits of our patience.
Imagine if the hardware were 10-100x faster, allowing our assistant more time to think3. Instead of blurting out a first thought, the assistant could quickly use its initial response to explore various follow-up questions and concepts before responding4. Now we’re talking!
Stockpiling companies’ customers face genuine issues that could be effectively addressed by the today’s AI, but only if the true power of the models can be revealed through faster hardware.5
Can someone free Jarvis?
GPU Bloat and How AI Chips Can Help
Fortunately, a few companies are quietly building custom AI silicon to unlock the responsiveness necessary for AI’s killer apps. Their rationale is straightforward: today’s AI runs on general-purpose parallel processors, which support more functionality than a given AI task requires. On the contrary, purpose-built AI ASICs have lower latency, higher throughput, and higher performance per watt for the given task.
But how much of this general-purpose overhead — let’s call it bloat — exists? Enough that removal will unlock the responsiveness needed for AI’s killer apps?
Let’s use math to illustrate the problem and find out.
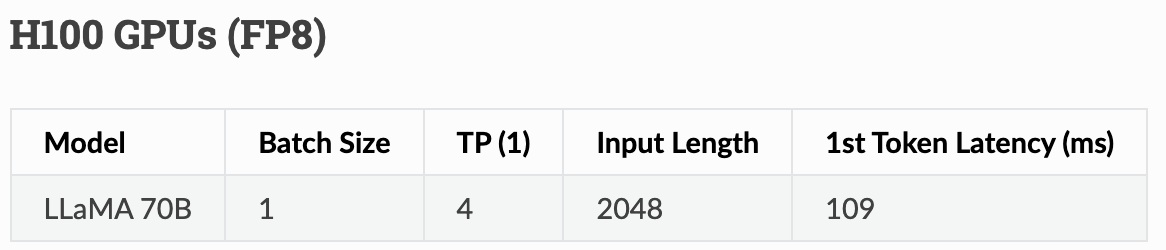
We’ll look at Meta’s LLaMA 70B model running on four state-of-the-art NVIDIA H100s.
In the simplest sense, LLMs spend their cycles loading data and doing math6. We’ll refer to the time it takes to load data as memory latency and the time to do math as math latency.
In the upper limit on performance, an ASIC could be sized with enough parallel compute to render math latency negligible relative to memory latency7. This is a “memory bound” scenario, meaning the time it takes to load the weights from memory is much longer than the time to do the math.8 Total latency is therefore the memory latency.
Let’s compute the memory latency with the best memory bandwidth possible at 3.9TB/s per GPU 910.
We can compute the time to load the data as follows.
We need to load the weights of the LLaMA 70B model into memory — 70 billion parameters. If we quantize LLamA 70B to FP8, each parameter is a single byte. Thus, the size of data is 70GB (70B parameters * 1 byte/parameter).
The memory bandwidth for the system is the sum of each GPU’s memory bandwidth11, which for an H100 NVL is 3.9TB/s. There are 4 GPUs, so the aggregate bandwidth is 15.6 TB/s (4 * 3.9TB/s).
We can now estimate the memory latency.
The memory latency for FP8 inference on 4 NVIDIA H100 GPUs is 4.5ms.
According to NVIDIA, 109ms is the observed time-to-first-token latency12 of FP8 LLaMA running on 4 GPUs with a 2048 input length prompt13 and batch size of 1.
Let’s define GPU bloat as the added latency due to the general-purpose nature of GPUs.
In our case, the observed latency is 109ms and the ideal latency is 4.5ms, so the bloat is an additional 104.5ms added to the time-to-first-token latency.
What contributes to this bloat? As discussed in previous posts14, the general purpose nature of GPUs comes with overhead. In this case, many factors including inefficient memory access patterns, CUDA kernel setup and teardown overhead, thread management and resource contention, and superfluous control logic all contribute to bloat.
Without bloat, an AI ASIC would experience a 24x faster time-to-first-token.
Of course, this hypothetical 24x improvement is a best case scenario. Furthermore, the bloat and speed up calculations are specific to a certain batch size, quantization, and prompt length; the point of our napkin math is to simply illustrate GPU bloat and the opportunity for custom AI hardware.
Any significant reduction in latency would meaningfully pull forward AI innovation and adoption. Remember — the faster it is, the more we will use it.
Every Last Drop Of Latency
Napkin math is easy, but chip design is hard. In practice, an ASIC wouldn’t actually meet the theoretical latency of 4.5ms due to things like difficulties in maximizing memory bandwidth utilization and chip area, and other constraints like managing cost and energy consumption.
Imperfect utilization is OK — the main goal is removing as much bloat as possible.
How much bloat can realistically be removed? It’s the classic “flexibility versus latency” trade-off. Achieving the absolute minimal latency would necessitate a chip designed specifically to LLaMa’s unique implementation details.
This implies a spectrum in the flexibility and latency of AI silicon, ranging from general AI accelerators with higher latency but greater flexibility to model-specific chips that prioritize achieving the lowest latency.
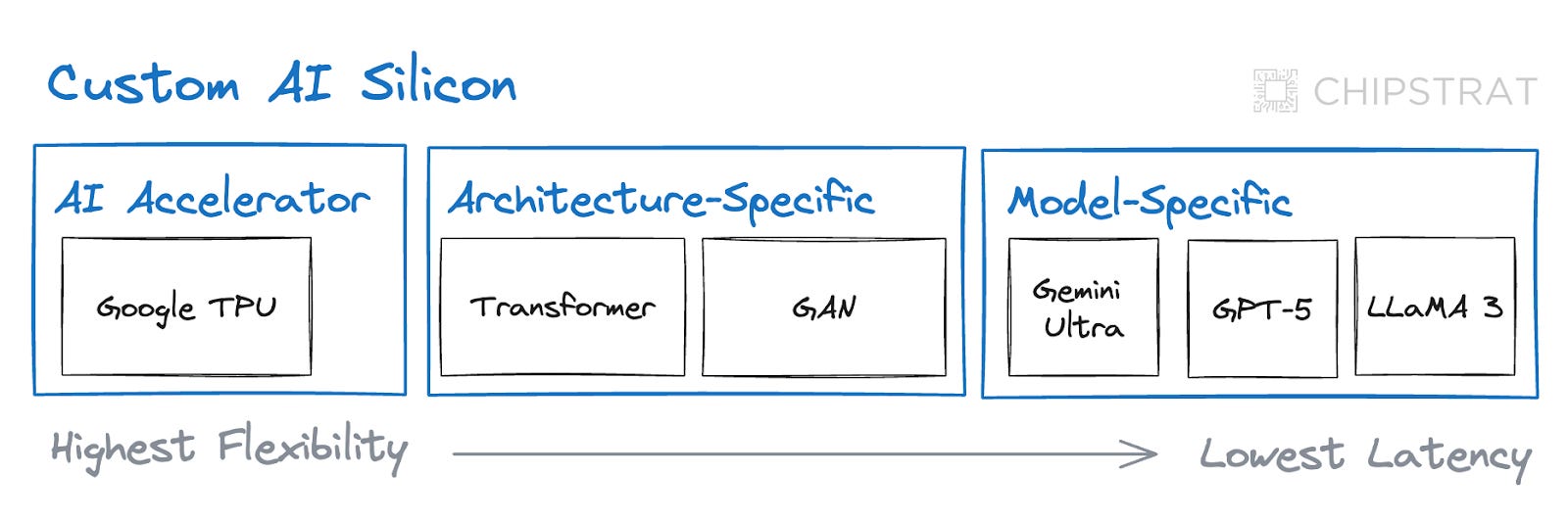
In this trade-off hierarchy, general AI Accelerators like the Google TPU support a variety of neural network architectures such as transformers, convolutional neural networks (CNNs), variational autoencoders (VAEs), and generative adversarial networks (GANs). These chips are the most flexible but the least optimized for a specific AI task.15
Put simply: they remove a lot of bloat but leave some latency on the table in return for flexibility.
Architecture-specific ASICs are optimized for a specific neural network architecture such as transformers ASICs or GAN ASICs. These remove even more bloat but are limited to a particular architecture.
Considering the potential $1B+ cost for training foundational models, investing $50-$100M in architecture-specific chips that deliver 10x reduced latency is increasingly viable1617. At scale, inference providers using these chips will see lower operating costs thanks to ASICs higher performance-per-watt than GPUs.
Finally, model-specific ASICs are chips specifically designed for a particular AI model or a very narrow family of models. While currently hypothetical, this hardware would be optimized for the specific computational needs, memory access patterns, and data flows of a particular model. It’s not yet clear how much bloat is left on the table by architecture-specific chips, but this model-specific approach would squeeze out every last drop of latency still available.
Model-specific ASICs make sense in a world of AI killer apps where responsiveness is king and massive datacenter AI loads incur significant operating costs.
Etched
Cupertino-based Etched is one example of a company quietly building architecture-specific AI ASICs to unlock the responsiveness needed for AI’s killer apps. Etched is in stealth mode but recently shed light on their approach in this recent podcast with Patrick O’Shaugnessy. Here’s Etched CEO Gavin Uberti explaining the benefits of transformer ASICs:
Gavin: Imagine a chip where you take the transformer model, this family, and burn it into the silicon. Because there's no flexible ways to read memory, you can fit an order of magnitude more compute and use it to more than 90% utilization. This lets you … get responses back in milliseconds instead of seconds.
Patrick: How much better [than NVIDIA’s GPUs] do you want to be? Is it 5x, 10x?
Gavin: It's got to be more than 10x. But because we're able to specialize [with a transformer ASIC], you can get a huge amount more compute on these chips.
And let me just give a concrete example here. It takes about 10,000 transistors to build a fused multiply add unit. That's the building block of any matrix multiplier. And NVIDIA has not that many on their chip. Only about 4% of that chip is the matrix multipliers because to feed them requires so much more circuitry. That's the cost of being so flexible. We will have more than an order of magnitude more of these multipliers – an order of magnitude more raw FLOPs.
And of course, turning that into a useful throughput — that is still not trivial. You need a very good memory bandwidth there as well.18
But the reason I can confidently say… that we will be better is I already know the metrics on our chip. I already have PPA figures19. We will just have so much more raw compute, substantially more than an order of magnitude. That's not just for compute, but also for latency.
It sounds like Etched is working to remove GPU bloat with a transformer chip and they claim to be making significant progress. Sure, there are a million hurdles between napkin math and holding a taped out chip, but our first principles thinking suggests this is an opportunity worth pursuing. The question at hand is how much bloat startups like Etched can actually remove.
AI’s killer apps are waiting.
4% utilization - is that for real?
Gavin’s claim that only 4% of GPU chip area is specific to the math at the heart of AI is a bit shocking. It implies the other 96% of the chip is overhead or unused during LLM inference.
That’s like renting a plane with 175 seats to fly a team of 7 executives. Wouldn’t it be a better use of money and energy to fill more seats on the flight or get a smaller plane?
Still, NVIDIA sold nearly $15B of these chips in a single quarter and has a customer backlog extending 36-52 weeks! That’s a lot of money for unused silicon.
There’s clearly a significant opportunity for low-latency inference chips.
For paid subscribers, I’ll dig into Gavin’s claim to see if it’s credible or hyperbolic.