




GPU Networking Basics, Part 1
Communication during Training, Scale Out, Scale Up, Network Architectures, Switches, etc.

We’re going to very gently discuss networking and GPUs. It’s an important topic, but it can feel boring or esoteric. Hang with me!
Motivation
Training an LLM requires a lot of floating point operations (FLOPs):
How long to train these models?
If a single GPU can produce about 2 PetaFLOP/s (2 * 10^15 floating point operations per second) and there are 86,400 seconds in a day, that equates to roughly 1.7 x 10^20 FLOPS. In the most ideal scenario, using a single GPU, you would need to train for approximately 16 years to reach 10^24 FLOPs.
16 years! Ain’t nobody got time for that!
How can we train LLMs in months or weeks? We need a lot of GPUs working simultaneously.
They’ll also need to talk to each other to share their progress and results as they work in concert. How does this communication happen? Networking!

No, no, not that kind of networking.

Yeah, that kind of networking! 😅
Connecting GPUs is actually a pretty interesting problem. Think about xAI needing to coordinate communication between 200K GPUs!
I mean, just listen to this entire 4 minute video with Elon. What an epic systems engineering problem to work on!
Network Switches
Let’s take xAI’s 200K GPU cluster as an example. How to connect them?
In an ideal world, every GPU could talk to every other GPU as fast as possible.
The first idea that comes to mind then: well, what if we directly connect every GPU?
No intermediate hops through a switch or another device would be needed, so it should be really fast!
This is a “full mesh” network.
But there are many practical reasons why a full mesh network doesn’t work at scale.
For example, to connect pairs of GPUs directly, each GPU would need 199,999 ports, and we would need ~20 billion total cables! Lol.
What if we introduce network switches? A network switch is a specialized piece of hardware that helps route data efficiently between multiple devices—in this case, GPUs.
Instead of connecting every GPU to every other GPU directly, GPUs are connected to a switch, and the switch manages communication between them.
A single network switch for 200,000 GPUs would simplify cabling to one per GPU, so down from 20 billion cables to only 200K!
But the switch would still require 200,000 ports, which isn’t feasible.

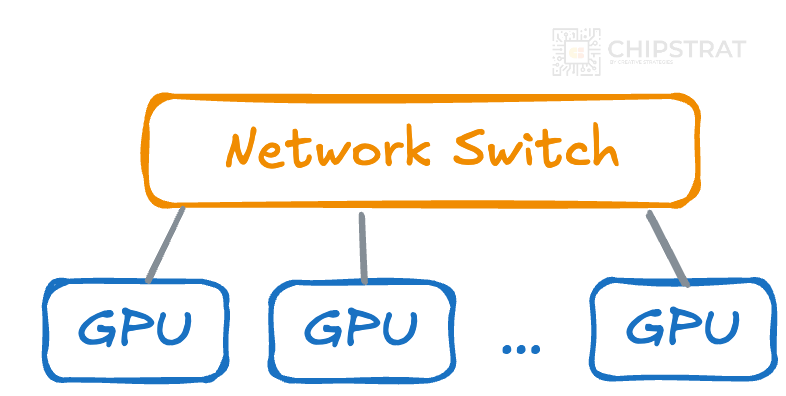
Obviously one massive switch isn’t going to cut it, which means we’ll need hierarchical switching.
Leaf-Spine Topology
Instead of using one massive switch to connect all GPUs, we could organize the network into layers of switches:
Each switch in this hierarchy could be smaller and connect only a subset of GPUs, making it more manageable in size and cost.
With this solution, GPUs don’t need to have thousands of direct connections anymore, and neither do the switches!
However, the trade-off is that data must pass through multiple switches when GPUs on different branches need to communicate, introducing additional latency.
To illustrate, consider two GPUs that are not connected to the same switch. Instead of a direct link, their communication must travel up to a higher-level switch and then down to the target GPU’s switch.
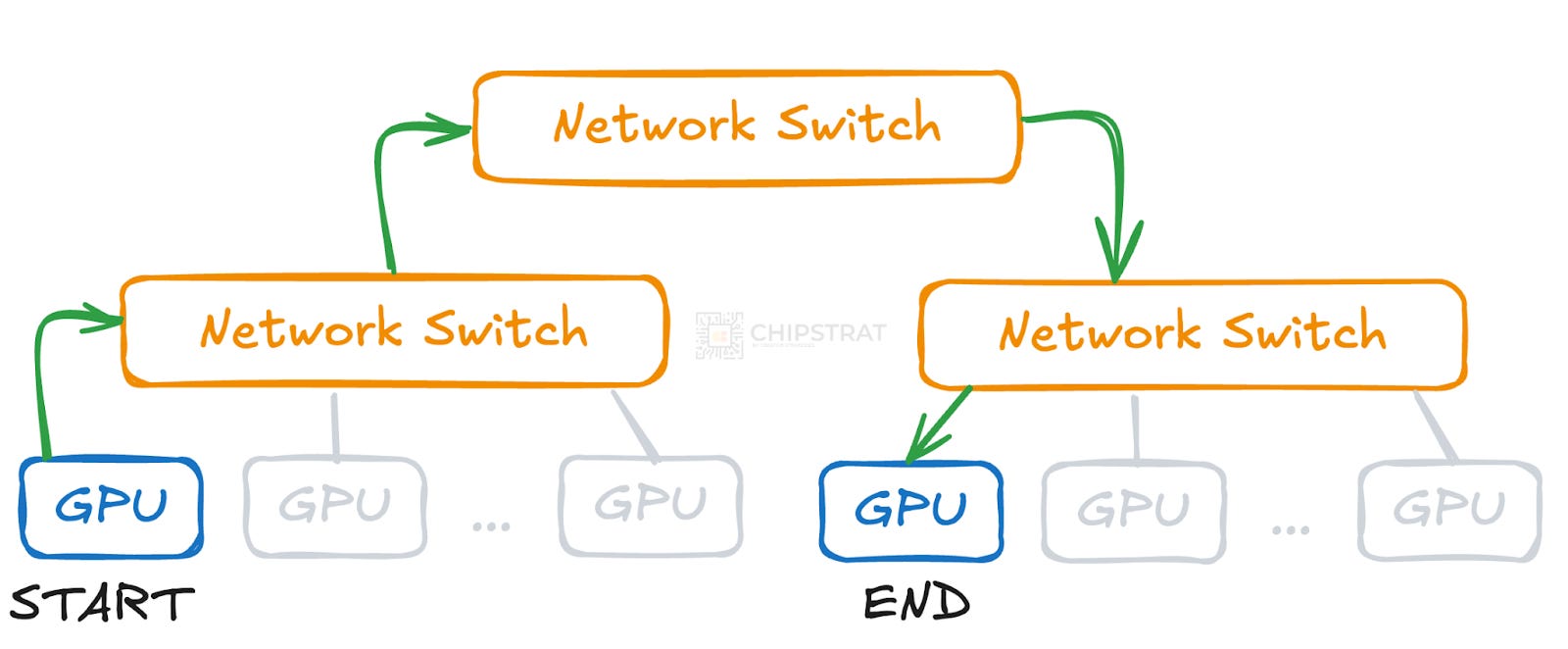
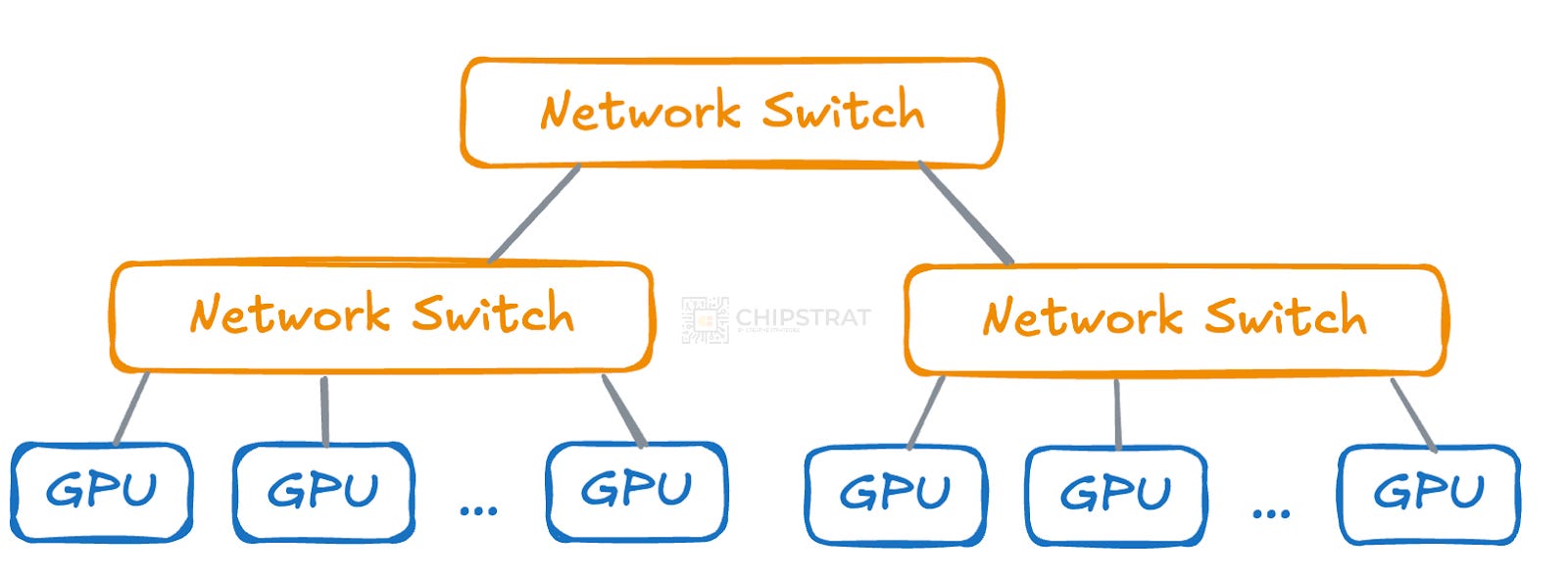
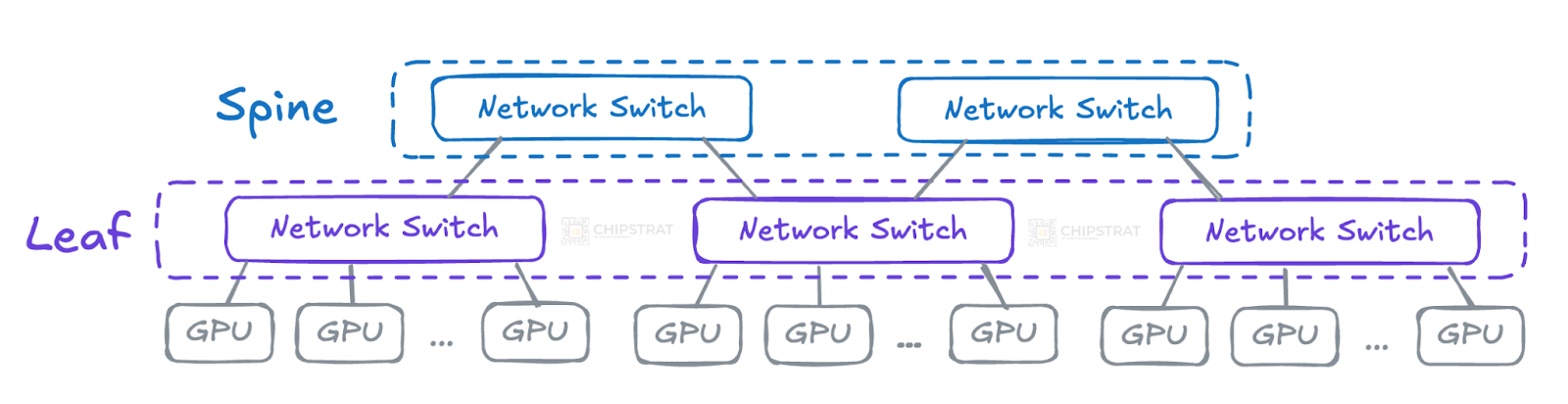
A two-tier architecture like this is often called a leaf-spine architecture or a two-tier Clos network.
Leaf switches connect directly to the compute, and spine switches connect the leaf switches:
Scale Out
How to get to thousands of GPUs?
Scaling out, or horizontal scaling, is how we expand the cluster by adding more GPUs and network switches. This helps distribute the training workload across more hardware, reducing the time needed to train an LLM.
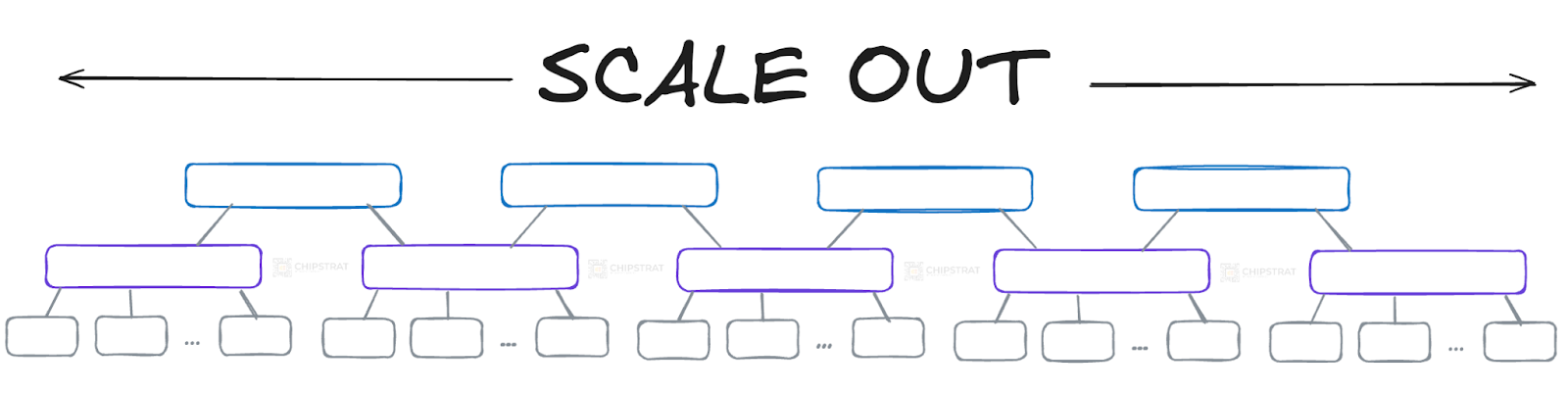
How do these GPUs and switches communicate with each other? Scaling out uses Ethernet or InfiniBand, both of which provide the high-speed networking required for GPU-to-GPU communication.
InfiniBand is a proprietary Nvidia offering (acquired via the Mellanox acquisition) and was historically preferred in large-scale AI clusters due to its lower latency and higher bandwidth compared to high-performance Ethernet variants like RoCE (RDMA over Converged Ethernet).

Ethernet is increasingly preferred for new training clusters. As Jensen shared in this week’s Nvidia GTC keynote, Elon’s xAI built the biggest training cluster (Colossus) with Nvidia’s Spectrum X Ethernet.
Scale Up
Scaling out works for a while, but eventually, physics and economics push back. More devices and switches mean additional latency from extra hops, higher power consumption, and rising costs. At some point, scaling out alone is no longer the best solution.
This leads us to another approach: scaling up or vertical scaling.
Scaling up means increasing the computational power per node rather than adding more nodes.
Instead of each leaf switch connecting directly to individual GPUs, it could connect to servers that each contain multiple GPUs—say, eight per server. This reduces the number of direct network switches and cables needed:
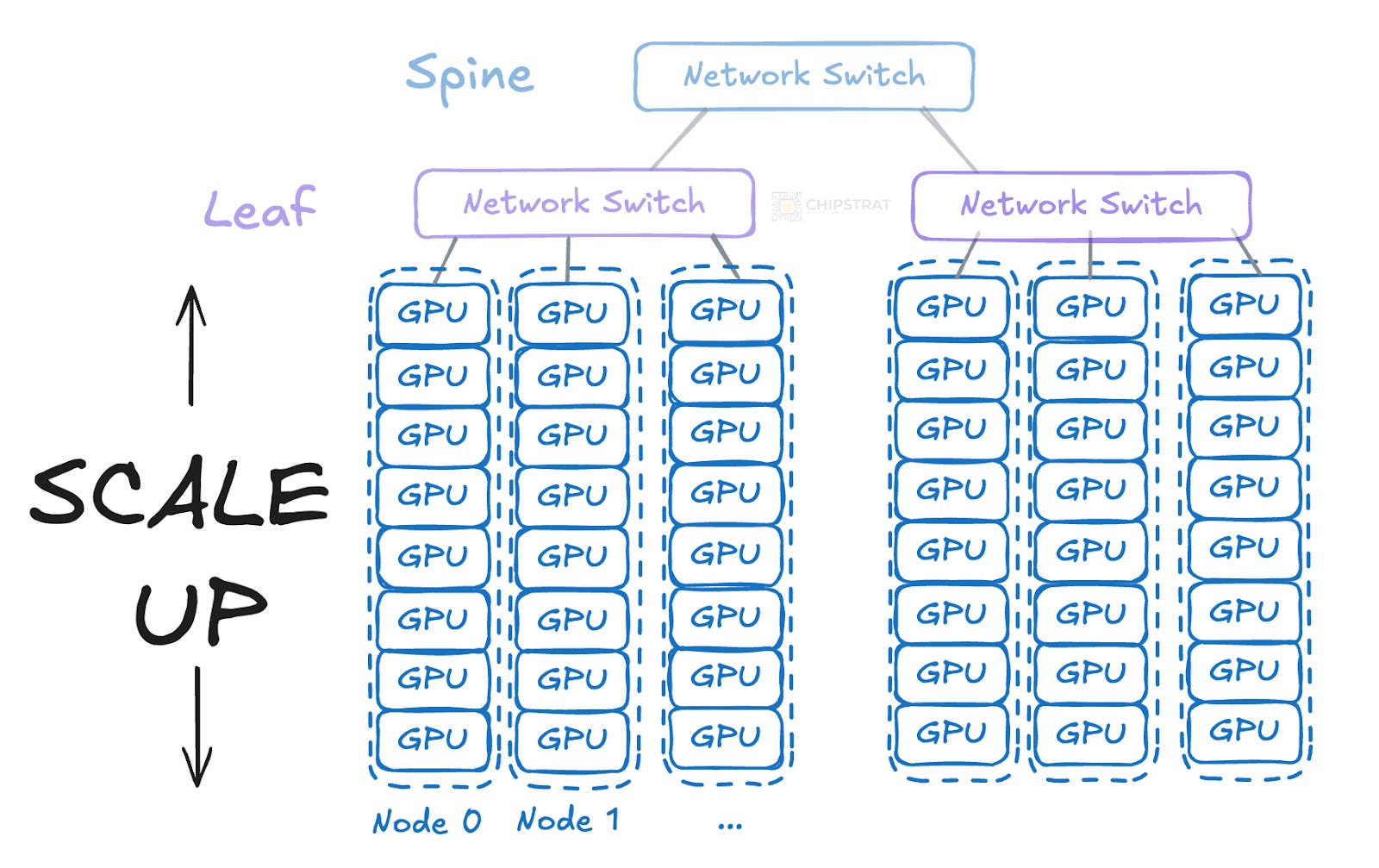
As an analogy, in the early days of web scaling, fast-growing companies might first upgrade a server by adding more CPU cores and memory. That’s vertical scaling. When a single machine wasn’t enough, they would add more servers and a load balancer to distribute traffic. That’s horizontal scaling.
The astute observer might wonder how these scale up GPUs talk to each other. Don’t they need to be connected via a network switch still? And if so, how is this different from scaling out?
Very good observation!
Intra-node vs Inter-node
Communication within a server node is called intra-node communication.
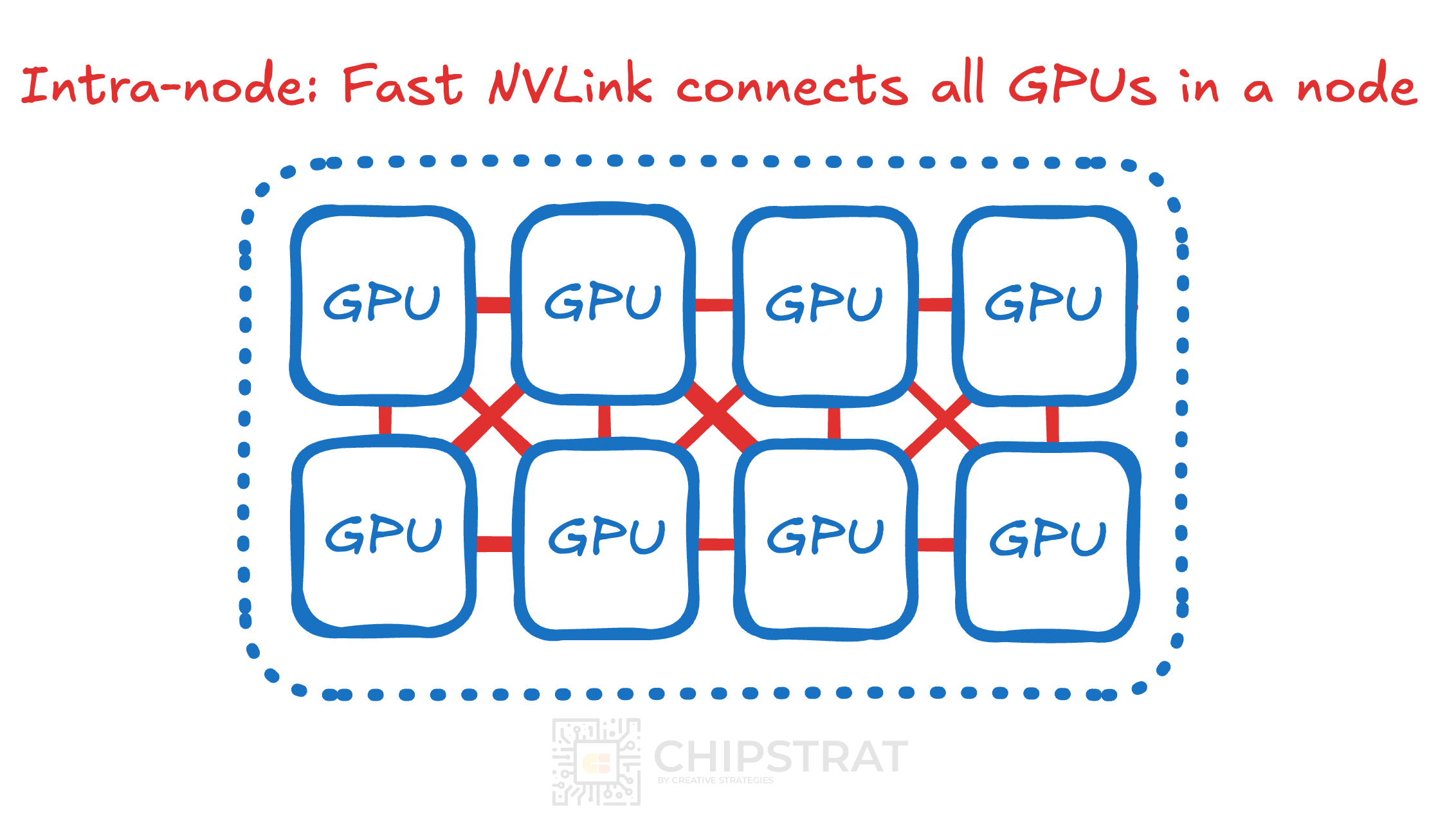
Communication between GPUs on different servers is called inter-node.
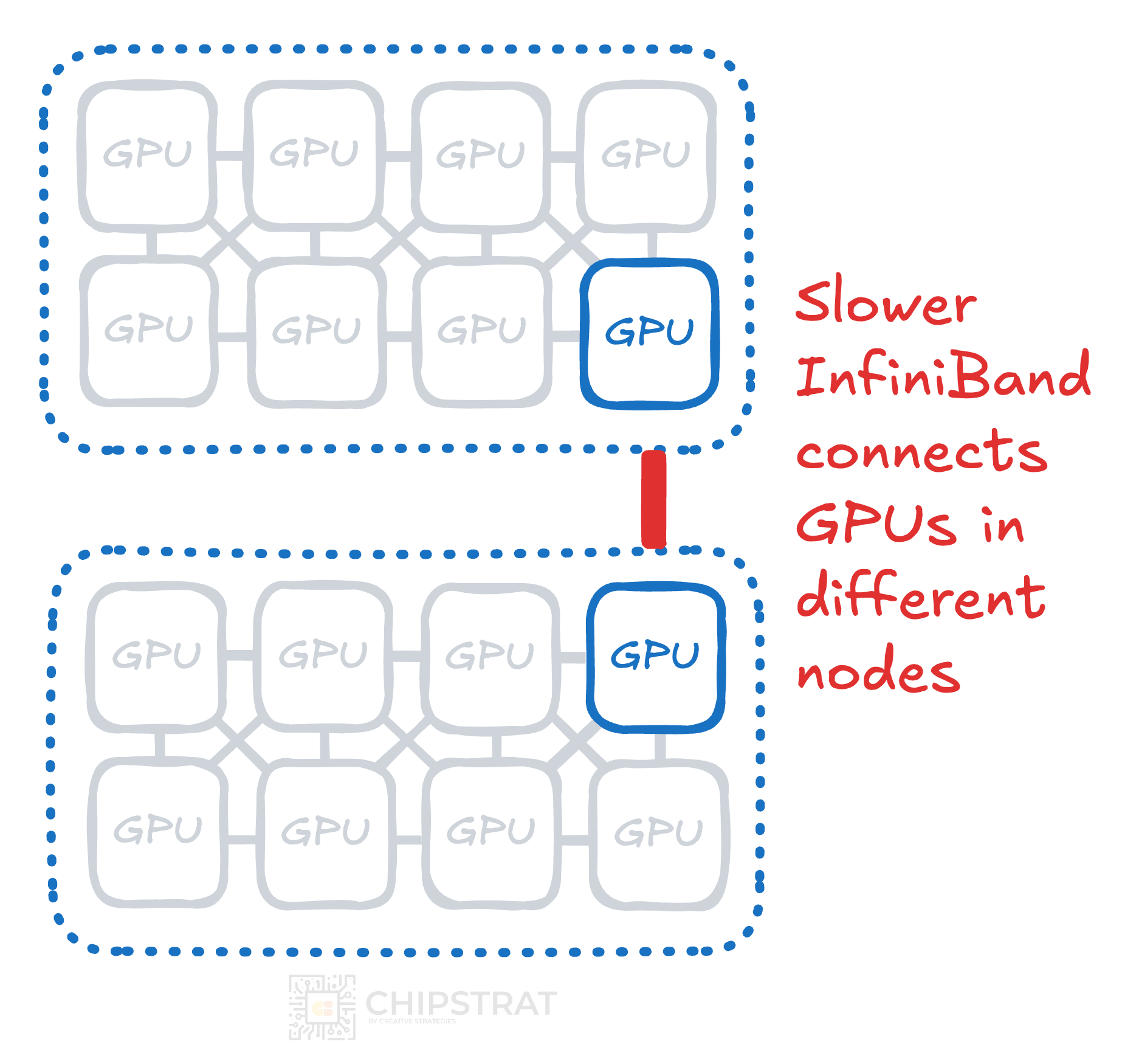
It turns out neighboring intra-node GPUs can communicate more quickly and at a higher bandwidth than using inter-node Infiniband or Ethernet technologies.
Why?
This is primarily due to the physical proximity of the GPUs and the specialized interconnect technologies employed. These technologies utilize direct, short, and optimized signal traces that are often integrated directly onto the same circuit board or within a shared package. This reduces signal travel distance and minimizes latency.
For example, here’s the routing for AMD’s Infinity Fabric as shared in the 2018 IEEE International Solid-State Circuits Conference - (ISSCC) proceedings

Since GPUs within a server are directly connected, they can avoid much of the overhead associated with inter-node communication between GPU servers. On-package routing improves efficiency by keeping trace lengths short, reducing propagation delay, and minimizing signal degradation.
External connections like Infiniband and Ethernet often require additional signal integrity components—such as repeaters, retimers, and error correction mechanisms—to maintain reliable transmission over longer distances. These can introduce incremental latency and increase power consumption,
I like to think of intra-node communication like NVLink and InfinityFabric as the Autobahn: designed to go fast without interruptions.
Inter-node communication is like a two-lane highway: it’s slower, you can’t fit as much traffic, and you might have to slow down to go around a tractor during spring planting or fall harvest (i.e. deal with congestion)

Communication During Training
It’s helpful to remember of how neural networks are trained to understand communication challenges.
During each training cycle, the network first performs a forward pass, where input data flows through layers of the network to produce a prediction. This prediction is then compared to the correct answer using a loss function, which quantifies how far off the prediction was.
The heart of learning happens during the backward pass, where an algorithm called backpropagation calculates how much each weight in the network contributed to the error. Using this information, gradient descent adjusts all weights in the direction that reduces the error—essentially turning billion of “knobs” to gradually improve the network's accuracy. With each iteration, these incremental adjustments push the neural network closer to making reliable predictions on new data.
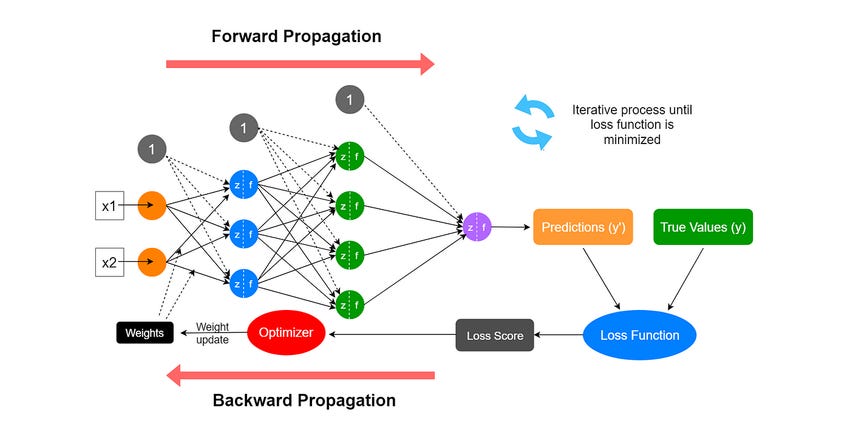
Each GPU computes gradients for weight updates based on the error from the forward pass, but since the GPUs each work on different data subsets, these gradients are only partial. To ensure that all GPUs apply the same updates and remain in sync, gradients must be aggregated and averaged across GPUs.
This process, known as all-reduce communication, allows GPUs to exchange and distribute the final computed values before updating their local models. By maintaining global consistency, this prevents model drift and ensures effective distributed training.
The latency of this all-reduce communication directly impacts training efficiency.
There are other collective operations too, for example these supported by Nvidia’s NCCL software library: AllReduce, Broadcast, Reduce, AllGather, ReduceScatter.
So training clusters ideally use the highest bandwidth and lowest latency communication possible.
And, as we saw with DeepSeek V3, there are software approaches to overlap communication and computation to reduce the amount of GPUs idling and reduce the impact of communication constraints.
Conclusion
That’s it for this part 1 article. I told you it would be gentle!
There’s a lot more to talk about. Actual massive clusters aren’t full mesh; it’s more complicated.
We will also eventually cover topics like inference communication needs and how they differ from training, front-end vs back-end networks, optical communication, and so on.
But I hope you got far enough to start to have a bit of confidence when you see a diagram and some docs, for example this Nvidia SuperPOD Compute Fabric diagram, you can get a high-level understanding and ask questions to fill in the gaps:
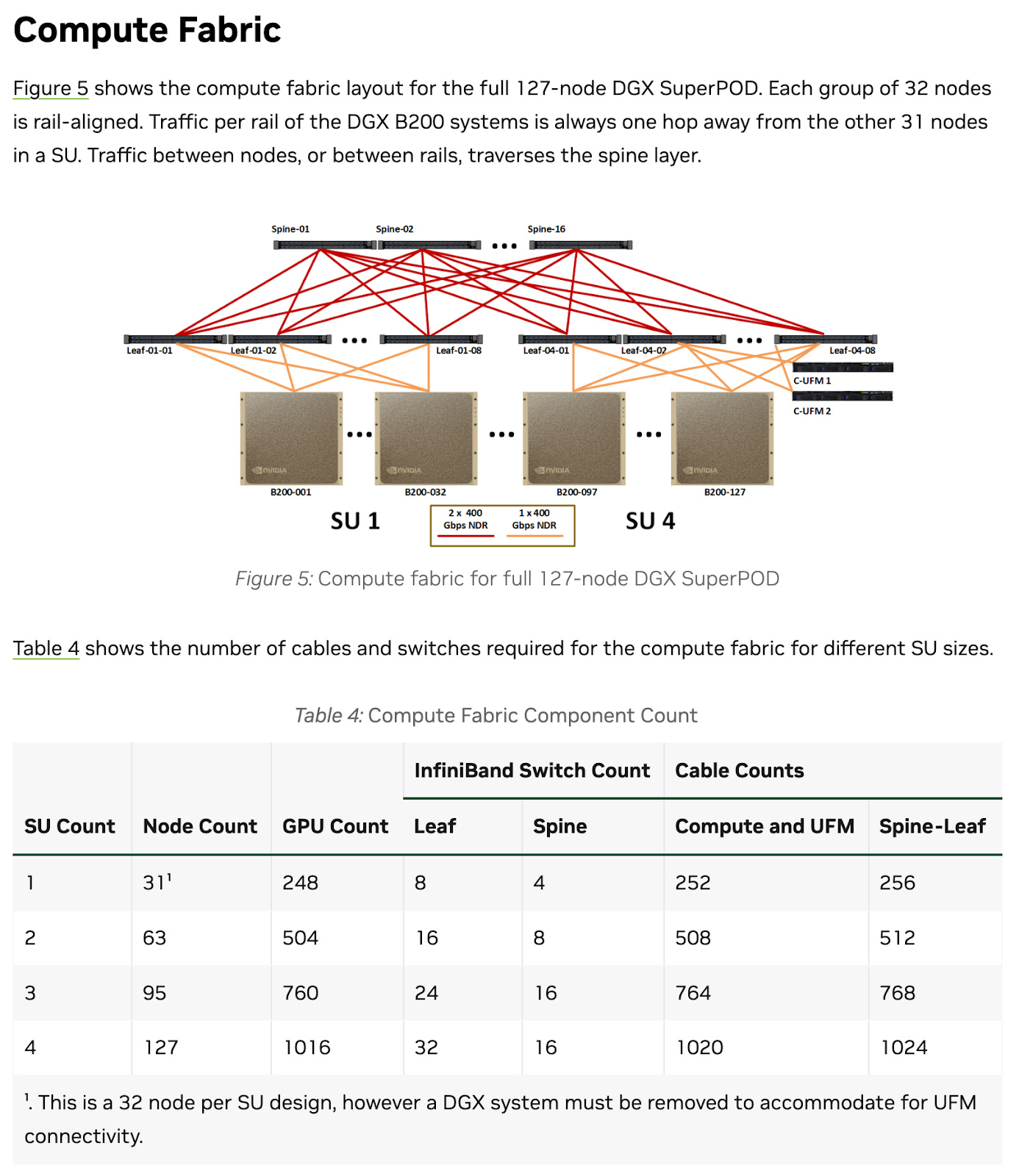
In the diagram above we see the spine and leaf switches helping with scale out, and the B200 servers scaling up.
From the table we can figure out that each Scalable Unit (SU) has 32 nodes with 8 GPUs per node. So this is scale out (32 nodes) and scale up (8 GPUs per node). Forget the details about “removing a DGX to accommodate for UFM connectivity”; the point is you can generally understand some of this now!
Good work!




