

Groq’s Business Model, Part 1: Inference API
Simplifying The User Journey, Business Model Innovation, Customer Benefits

Last week’s article discussed how Microsoft's stumbles erased Qualcomm's Copilot+ lead. It also compared Intel’s AI PCs to Apple Intelligence and finished with more nuclear power thoughts.

This post launches a series of articles unpacking Groq’s “ramp to hardware” business model.
Groq’s Business Model, Part 1: Inference API
In our recent conversation, Groq’s Mark Heaps mentioned the following three distinct revenue streams:
Inference API
Managed AI Services
AI Systems
In Mark’s words,
The way the business model works is we have deployment optionality and we call it a “ramp to hardware”.
At the bottom of the ramp, the long tail, you've got the developer community and they want API access. They're not going to buy multimillion-dollar racks of hardware. The landscape for AI changes rapidly – why would they commit to any one thing? It's sort of like leasing. They just want to be able to provision and buy per token and switch out models as needed. That gives them that rapid iteration. So why not serve that via our cloud?
Then we start getting some customers who say, “We want a cloud-like instance, but for compliance reasons and other things, we need to have a dedicated provisioned system. But you guys manage it.” And we can do that. That's the next stage of moving up the ramp.
Next you get people that say, “We want more than that. We want to actually have something that's a colo where we've got some equipment in our lab and some in a data center. You guys help us facilitate and manage that, and we will go up from there.”
Then you get to the announcement that just happened with Aramco Digital in the Kingdom of Saudi Arabia, where we're selling them and shipping them hundreds and hundreds and hundreds of racks. They're going to stand those up in their new data center in the region.
These are distinct offerings for different customers, yet each leverages Groq’s underlying hardware and software platform. The critical differentiation at each stage is the breadth of the user journey Groq solves on behalf of the customers. The pricing models differ accordingly.
Let’s dive deeper into each offering.
Inference API
Groq’s lowest barrier to entry service is an inference API, colloquially known as a tokens-as-a-service offering. This lightning-fast LLM inference is powered by Groq’s LPUs and made available to anyone with an API key.
User Journey
Groq’s Inference API abstracts away many steps of the user journey.
For example, with the Inference API, an app developer doesn’t need to rent hardware, figure out how to deploy a model, optimize the model, and write their own inference API. They simply generate an API token and start consuming the API from their app. They spend all their time powering their own generative AI features in their app, and no time on hardware or AI models.

Getting started can be as simple as a few lines of code.

Pricing Model
Groq’s API uses a consumption-based pricing model to align costs with usage. This model allows users to pay only for the resources they consume, which is perfect for any curious individual or company. It also incentivizes efficient API design and usage, encouraging developers to optimize their applications and avoid unnecessary API calls.
The pricing increases as the memory requirements increase; small models are cheaper than large models. Groq’s LPU has a small amount of SRAM per chip; running a 70B parameter model takes 576 chips. Groq reportedly can run Meta’s recent 405B Llama 3.1, although it’s not yet listed on the pricing page. If the number of chips increases linearly, a 405 billion parameter model would require something like ~3,300 LPUs, which will make for an expensive offering.

Business Model Innovation
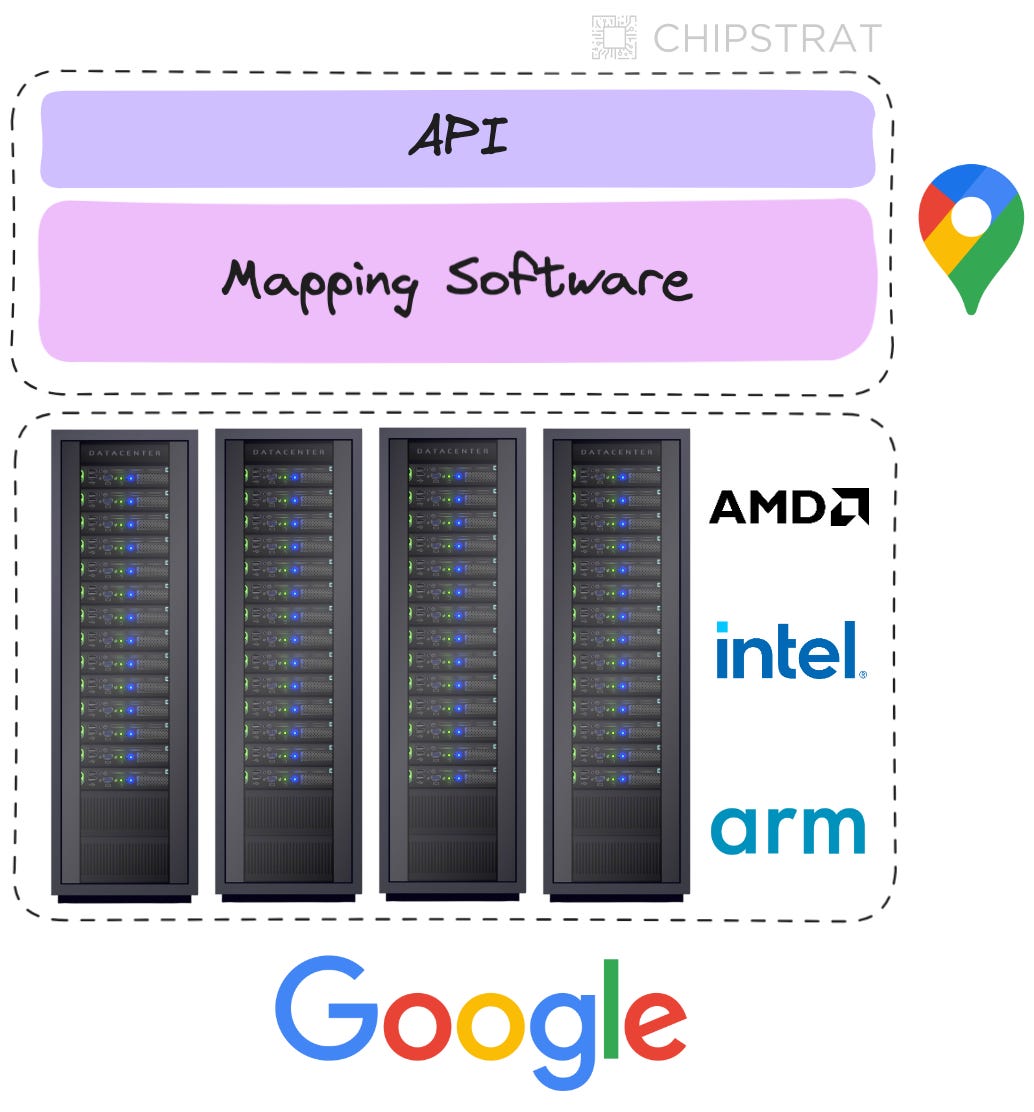
Selling access to an API is not new. For example, anyone can sign up for a Google Maps API key and make 100K JavaScript API requests for just $700 per month. Not bad!

Of course, Google is a software (advertising) company that powers its Maps API with merchant CPUs. Google’s special sauce is the mapping software. (Who knows, maybe Maps API runs on their internally designed, Arm-based Google Axion CPU.)
Inference APIs also exist, such as Microsoft’s Azure OpenAI API and Amazon Bedrock API. Groq is different, though—it’s a fabless semiconductor designer. The traditional business model for fabless chip companies is hardware sales. Groq is the first AI accelerator designer to provide a paid API powered by its hardware. It’s worth calling out Groq’s business model innovation, as others like SambaNova and Cerebras have followed suit.
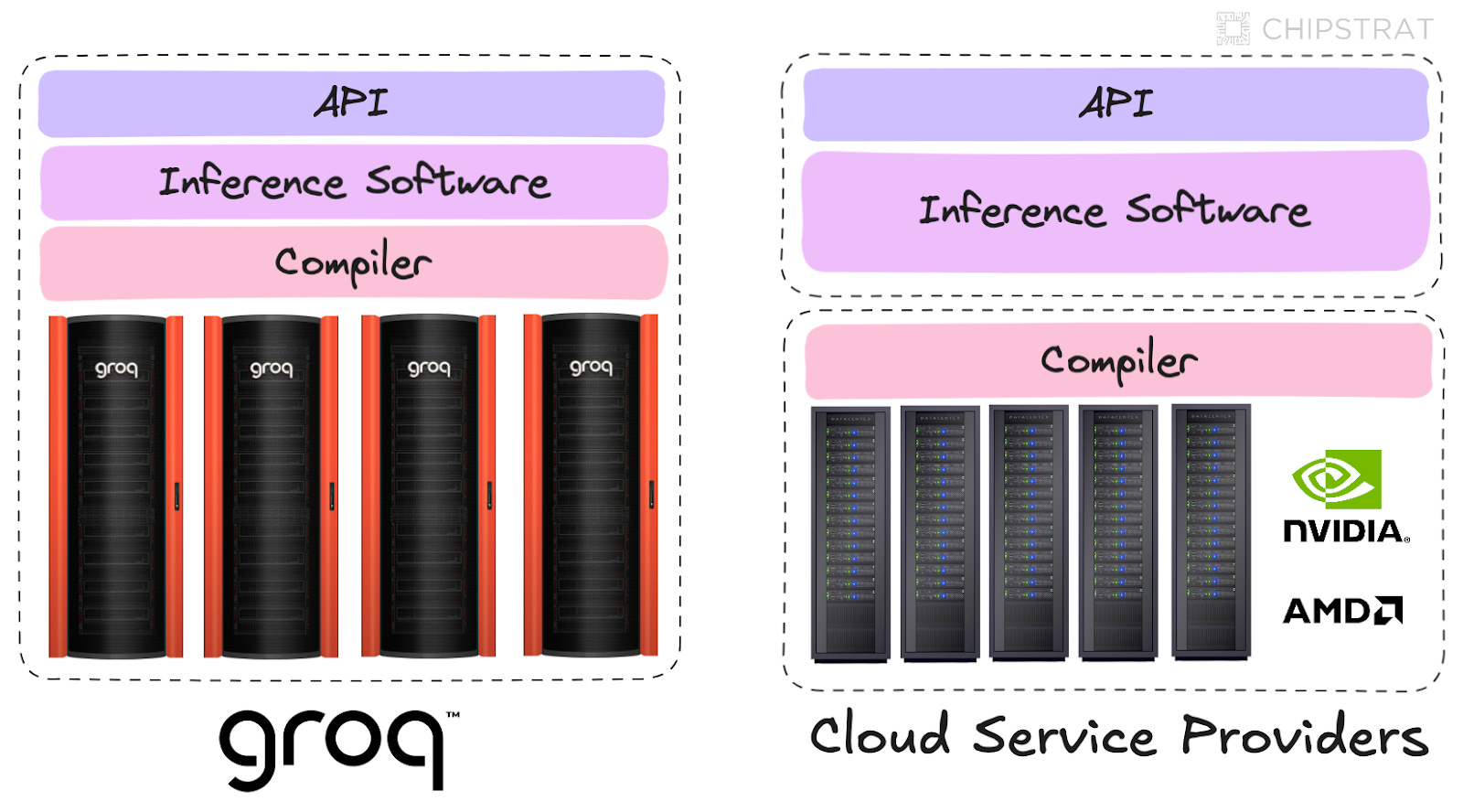
Groq invested heavily in designing and developing its LPUs, systems, data centers, compilers, ML software, and API service. Yet Groq suggests they can still run this fully integrated service profitably:
Mark Heaps: But what you have to remember with a lot of those folks is that they're brokering their compute from another cloud service, or they're waiting in line to buy GPUs so that they can stand up their stack, but they still have to buy those GPUs. Our economic model is profitable, and our tokens are profitable because it's completely us – we own the whole stack. We have our own data centers that we're standing up. We don't have any middlemen that we're having to pay for any of these services other than electricity. Electricity is really the big thing that everybody fights for.
We know what it costs to run our equipment. I often equate this to what Tesla did with car sales. Rather than going into a dealership model where you've now got to sell your units to all these independent dealerships around the country and then have them mark it up so that they can sell the vehicles, they said, “No, we'll just sell direct”. This is the same thing. When we didn't have a lot of folks jumping on Groq early, it just fueled our fire to say, “Okay, then we'll just do this direct model ourselves”. That's why we can compete in this space today and not lose money.
Austin Lyons: That makes a lot of sense. You're fully vertically integrated. There are no middlemen margins. It's not GPU’s huge 80% margins on top of the hardware or anyone else you're paying to host.
Customer Benefits
Groq’s inference API is the purest distillation of value for developers: acquire an API key and instantly unlock fast inference. This eliminates the capital expenditures and operational overhead associated with managing hardware, resulting in quick time-to-value and a low barrier to entry regardless of company size. Developers can focus on their core product—making their beer taste better, if you will—instead of the undifferentiated heavy lifting of infrastructure management, model deployment, optimization, etc.
Groq’s Benefits
First and foremost, Groq’s inference API is an organic means of showcasing the LPU's speed. They aren’t just publishing a metric but a “try it for yourself” product.
Secondly, setting up and managing a data center of LPUs gives Groq credibility with prospective hardware customers. The API is powered by a distributed system of LPUs — it works and is fast! Customers do not need to take a leap of faith. As Levar Burton would say,

By dogfooding, Groq can also advise prospective hardware customers on best practices for managing such a system.
Additionally, the API allows Groq to learn from its 500K users. How does the system perform under heavy load? Can the compiler handle different models from different providers? Are there previously unforeseen use cases that stress the architecture?
Interestingly, by cultivating an ecosystem of developers already familiar with high tokens/sec inference, Groq is developing the market on behalf of their prospective hardware customers. For example, there are now developers in proximity of the Middle East who are building high throughput Gen AI applications on Groq and are thus primed to benefit from lower network latency of a local Groq data center :
Mark Heaps: Aramco Digital has committed to building the world's largest AI inference-focused data center. Our massive developer community would love to have that instance and still use Groq in this part of the world.
And so now Aramco will have access to our user base and say, “Hey, why not access your tokens over here?” So it's a great partnership. You can buy hardware from us, and we have a massive pipeline of customers that are trying to get onboarded. And so there's a great opportunity all around.
This 500K developer ecosystem has driven significant brand awareness too. Groq has viral coverage on CNN, Stratechery, Hacker News, and X.
Finally, Groq is making some early revenue from this inference API. I have no idea what order of magnitude this revenue is. My hunch is that the goal of the inference API right now is lead generation for future hardware sales.
Time will tell! The second-gen chip, which skips from 14nm down to 4nm, is set to tape out in late 2024 or very early 2025.
That’s all for Groq’s inference API for now. Our next post will unpack the remaining tiers in Groq’s “ramp to hardware” business model.