I haven’t posted an educational update in a while, so today let's take a closer look at high-bandwidth memory.
Motivation
Generative AI is everywhere, from powerful cloud models to the promise of AI on our phones and wearables. But the GenAI explosion wouldn’t be possible without memory technology innovation. Specifically, high-bandwidth memory (HBM) has been crucial to enabling the recent success of massive cloud AI models.
LLMs and Memory
Let’s briefly review how large language models (LLMs) function to understand their memory demands and illustrate the need for HBM.
LLMs are layered networks of interconnected “neurons” with weighted connections. These weights determine the strength of influence between neurons. During training, the model is exposed to vast amounts of data and adjusts these weights. The final set of weights represents the model’s learned understanding of words, concepts, and grammatical structures.
For today’s topic, the key takeaway is that the model becomes “smarter” as the number of weights (the neural network size) grows. Larger networks with more weights can capture more nuanced relationships and complexities within the data, leading to more sophisticated language understanding and generation capabilities.
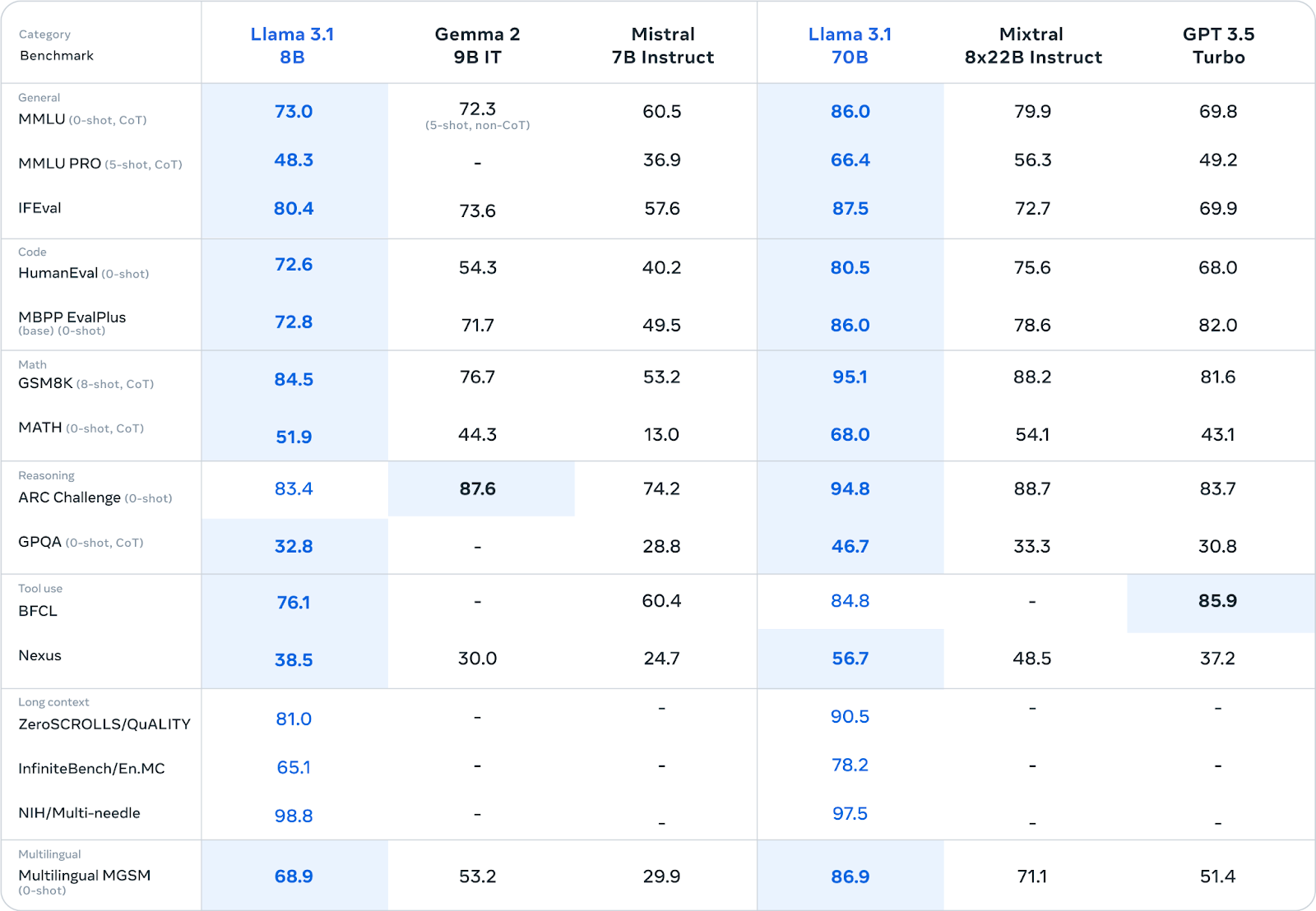
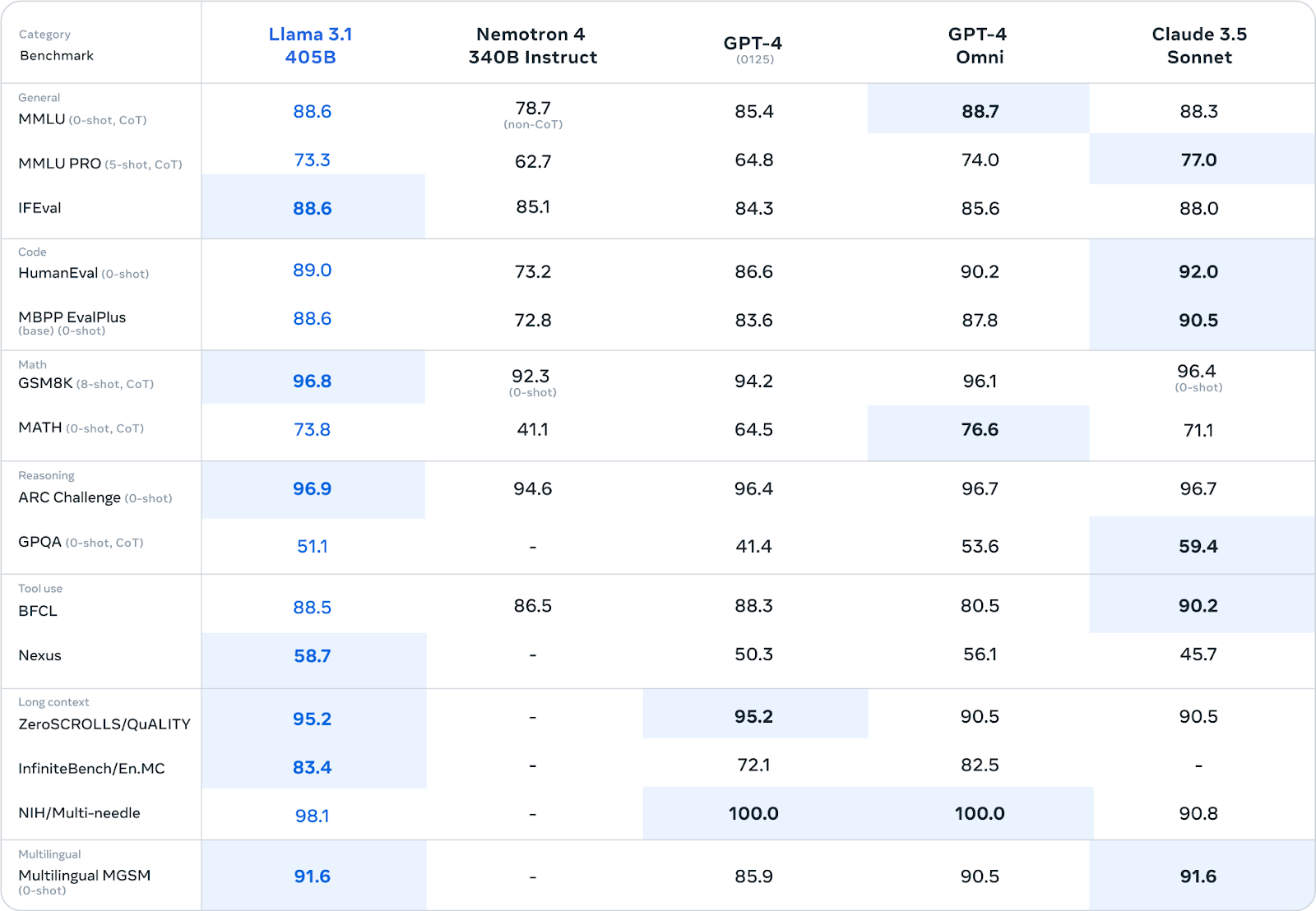
We see this with Meta’s Llama models. The largest model, 405B, has 405 billion parameters (weights) and outperforms the 70B and 8B models.
The 70B model outperforms the smaller 8B model. Source
405B is smarter than both 70B and 8B.
I like to think of the 405B as a bigger “brain” than the 70B and 8B since it has more neurons.
What limits the size of this brain? Why stop at 405B parameters?
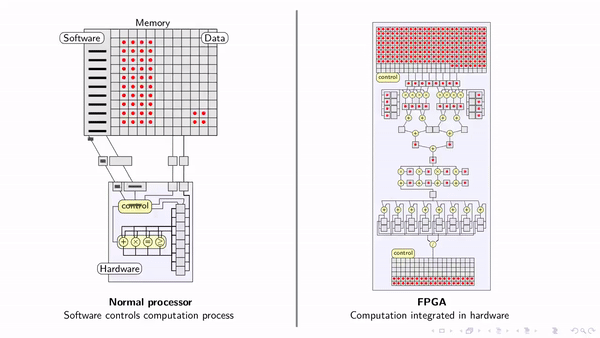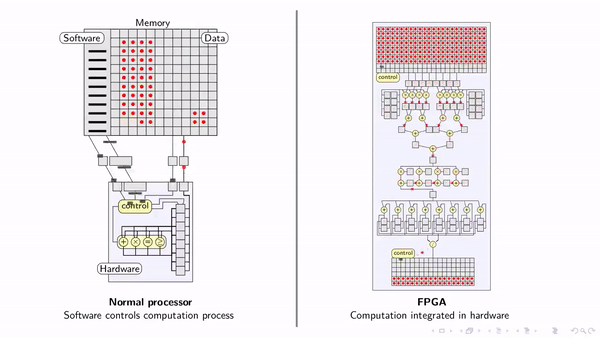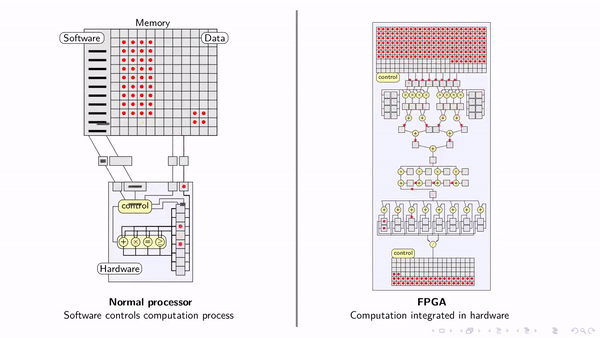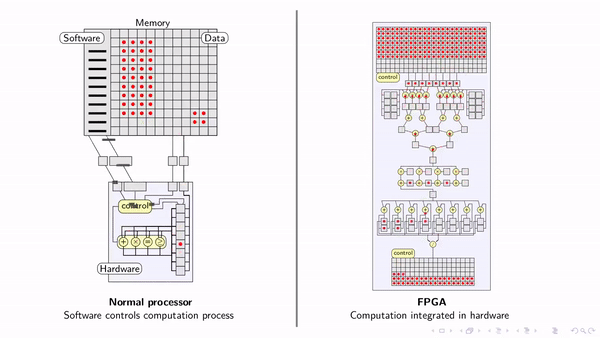
LLMs rely on AI accelerators like GPUs to function, and these chips have a finite amount of memory to store the model’s weights. As models grow larger with an increasing number of parameters, the demand for memory capacity on the chip grows proportionally. Ideally, AI hardware would have unlimited memory to store incredibly massive models, and retrieving these weights from memory would be instantaneous so that computation isn’t bottlenecked by memory access wait times.
In reality, hardware has finite memory capacity, which restricts the maximum model size that can be deployed. Moreover, accessing this memory isn’t instantaneous; it takes time to retrieve each parameter from memory.
Thus, there’s a balance between retrieval latency and model size—larger models mean longer waits unless memory bandwidth also increases. (Increased memory bandwidth enables more data to move simultaneously, like using larger pipes.)
In practice, LLMs are restricted by both memory capacity and bandwidth availability.
HBM
This is where High-Bandwidth Memory (HBM) comes into play.
HBM has a compact 3D stacking design, which places memory layers in a vertical arrangement close to the processor. This configuration shortens connections between memory and processor, reducing both latency and the energy needed for data transfer. As a result, HBM delivers higher bandwidth with a lower power consumed per transferred bit of data.
Furthermore, stacking memory enables more capacity; an eight-story hotel has more bedrooms than a single story motel.
HBM also increases bandwidth via a “wide interface” that provides many data channels between memory and the processor to support high-volume, simultaneous data transfers. Each channel functions independently, so adding channels (“widening the interface”) increases total throughput.
Can’t fit on a chip
Yet even with HBM, LLMs push the limits state of the art hardware.
As explained by HuggingFace, Meta’s Llama 3.1 can’t fit on a single chip:
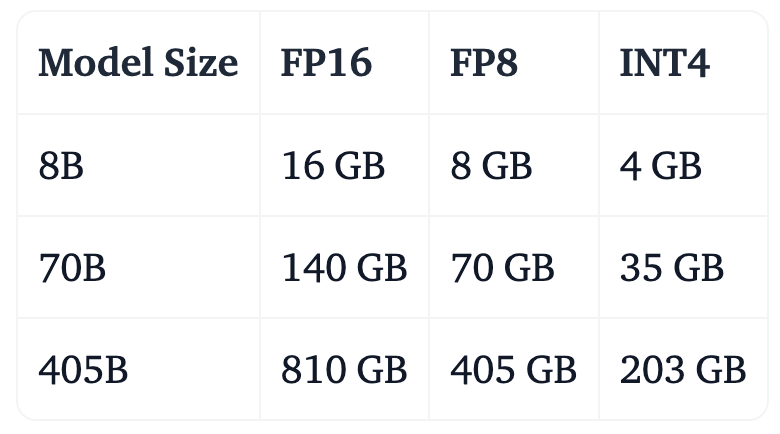
For inference, the memory requirements depend on the model size and the precision of the weights. Here's a table showing the approximate memory needed for different configurations:
Note: The above-quoted numbers indicate the GPU VRAM required just to load the model checkpoint. They don’t include torch reserved space for kernels or CUDA graphs.
As an example, an H100 node (of 8x H100) has ~640GB of VRAM, so the 405B model would need to be run in a multi-node setup or run at a lower precision (e.g. FP8), which would be the recommended approach.
Keep in mind that lower precision (e.g., INT4) may result in some loss of accuracy but can significantly reduce memory requirements and increase inference speed. In addition to the model weights, you will also need to keep the KV Cache in memory.
Llama 405B at half-precision (FP16) can’t even fit on a setup with 8 Nvidia H100s. And that setup can cost hundreds of thousands of dollars!
That seems a bit surprising! So why don’t these GPUs have more HBM? Couldn’t 405B fit into an 8-GPU server if each chip had more memory?
Adding more HBM to a chip isn’t without trade-offs. HBM faces challenges related to cost, power, and heat. Its intricate 3D stacking is expensive to manufacture and package. While HBM is efficient per byte of transferred data, the overall power consumption still increases with increased memory capacity and bandwidth. More power means more heat, which can cause thermal issues and impact reliability and performance.
Determining the precise amount of HBM per chip is also a system design and business decision. Can the additional cost for more HBM be passed along to customers, and if not, how might that impact gross margins?
AMD chose to include more memory with their MI300X GPU, and can fit 405B at FP16 into an 8-GPU server. From AMD,
Thanks to the industry-leading memory capabilities of the AMD Instinct™ MI300X platform, a server powered by eight AMD Instinct™ MI300X GPU accelerators can accommodate the entire Llama 3.1 model, with 405 billion parameters, in a single server using FP16 datatype.
AMD’s roadmap includes increased memory capacity and bandwidth for future accelerators like MI325X and MI355X.
Nvidia also plans to boost memory capacity and data transfer speeds in its future hardware. For instance, their upcoming Rubin platform will utilize HBM4, the next generation of high-bandwidth memory.
So what about edge devices like smartphones? Do they have HBM? After all, there are plenty of opportunities for LLMs at the edge.
The short answer is no.
Phones prioritize battery life, affordability, and compact design, all of which clash with HBM's characteristics.
Smartphones use a type of RAM called LPDDR (Low Power Double Data Rate), which works well for mobile devices given its low power consumption, high performance, and small form factor. That said, generative AI inference will demand as much smartphone RAM as possible, which is why we see Apple Intelligence limited to phones with at least 8GB RAM.
8GB can only support a small, not-so-intelligent model; on the other hand, do we actually need an AI model that encodes a PhD-level of understanding in every subject imaginable on our phones? Probably not — that’s what cloud models are for.
Memory Bandwidth Can’t Keep Up
HBM is a great technology, but generational performance improvements aren’t rapid enough.
From AI and Memory Wall, a great Berkeley paper, we can see that compute scaling drastically outpaces memory bandwidth scaling.
The availability of unprecedented unsupervised training data, along with neural scaling laws, has resulted in an unprecedented surge in model size and compute requirements for serving/training large language models. However, the main performance bottleneck is increasingly shifting to memory bandwidth. Over the past 20 years, peak server hardware floating-point operations per second have been scaling at 3x per 2 years, outpacing the growth of dynamic random-access memory and interconnect bandwidth, which have only scaled at 1.6x and 1.4x every two years, respectively. This disparity has made memory, rather than compute, the primary bottleneck in AI applications, particularly in serving.
A growing disparity exists between AI system’s computational capacity (FLOPS) and memory bandwidth. While FLOPS are increasing exponentially, memory bandwidth is lagging. Although AI chips can perform increasingly more calculations per second, they can’t move data around quickly enough, creating a performance bottleneck.
Think of it as an assembly line where the workers cooperate to build widgets. Imagine that the workers are given a new tool and can perform their assigned task in half the time. If the assembly line doesn’t speed up, the overall throughput won’t increase. Workers will simply spend more time waiting.
This motivates interesting questions: If memory bandwidth can’t keep up, can we reduce our dependence on moving data around? How can we be more thoughtful about the flow of data between where it’s stored and where it’s used?