



Memory: From Caches to Commodity Cycles
Memory Hierarchy, Memory Wall, HBM, Commodity Cycles, Historical Perspective, Beyond Silicon

Last week's article examined Arm’s transition from a legacy cost-based pricing model to a value-based approach. Does Arm have the right strategy and tactics? Read more here:

This week, we’re continuing our long-running educational series with an explainer on memory. We’ll cover the basics of memory, examine the implications for generative AI, and discuss the cyclical nature of the business.
Motivation
We’ve previously discussed logic chips that help systems think, and now we’ll discuss memory chips that enable systems to remember.
Although it might seem like a dry subject, a basic understanding of memory is beneficial, especially with the rise of generative AI. Leading AI models require substantial memory, leading to interesting trade-offs between model size, system performance, and cost.
The Basics
Let's start simple and study the memory technology used by CPUs.
A CPU's primary role is to execute instructions, which are the foundation of software programs. To execute these instructions, the CPU must access both the instructions themselves and the data upon which they operate. This is where memory comes into play: computers store instructions and data in memory.
CPUs sometimes use short-term memory, analogous to using a notepad to write down intermediate calculations when solving a math problem. At other times, long-term memory is required.
Balancing Trade-offs with Memory Hierarchies
Engineering is all about trade-offs, and memory is no exception. With every system, the design team must ask about
Capacity: How much information do we need to store?
Access Latency: How quickly do we need to retrieve that information?
Cost: How expensive is it to store this data?
CPU designers have devised an elegant approach to balancing capacity, latency, and cost with “the memory hierarchy.” This approach stores frequently accessed data in fast but costly memory and infrequently accessed data in slower, more economical storage.
Book Hierarchy Analogy
The memory hierarchy is best illustrated with the following “book hierarchy” illustration.
Imagine a college student working on their homework. It's impractical for them to keep every potentially needed book on their desk. Instead, they keep the most important textbook on the desk, while additional books are stored on a nearby shelf. For seldom referenced resources, such as for a thesis or final paper, the student can go to the campus library. If certain niche books are unavailable on campus, they can be requested from other libraries across the nation via interlibrary loan.
We can visualize this storage hierarchy as follows:
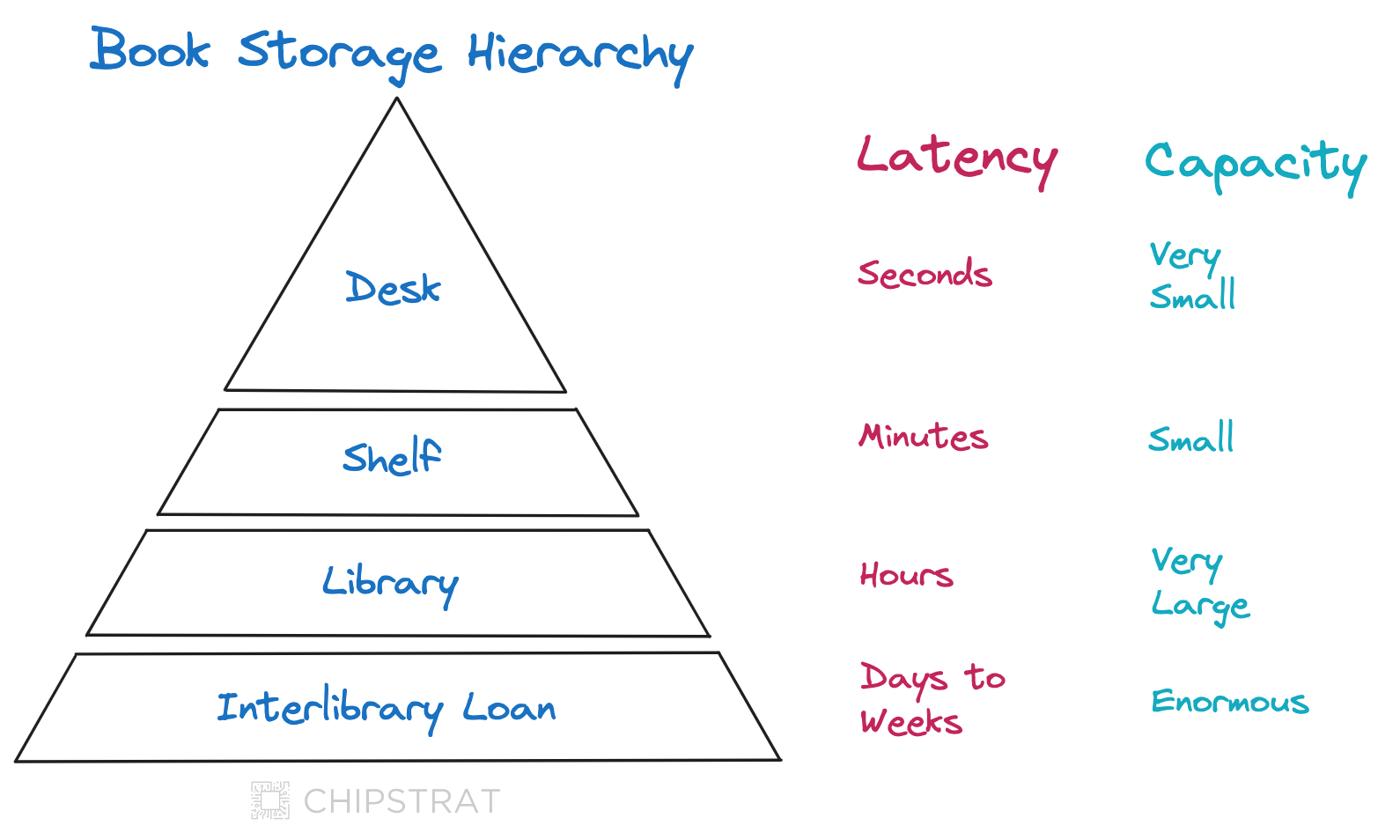
To optimize access, books must be placed carefully within the hierarchy. The most frequently referenced texts should be stored at the quickest retrieval levels.
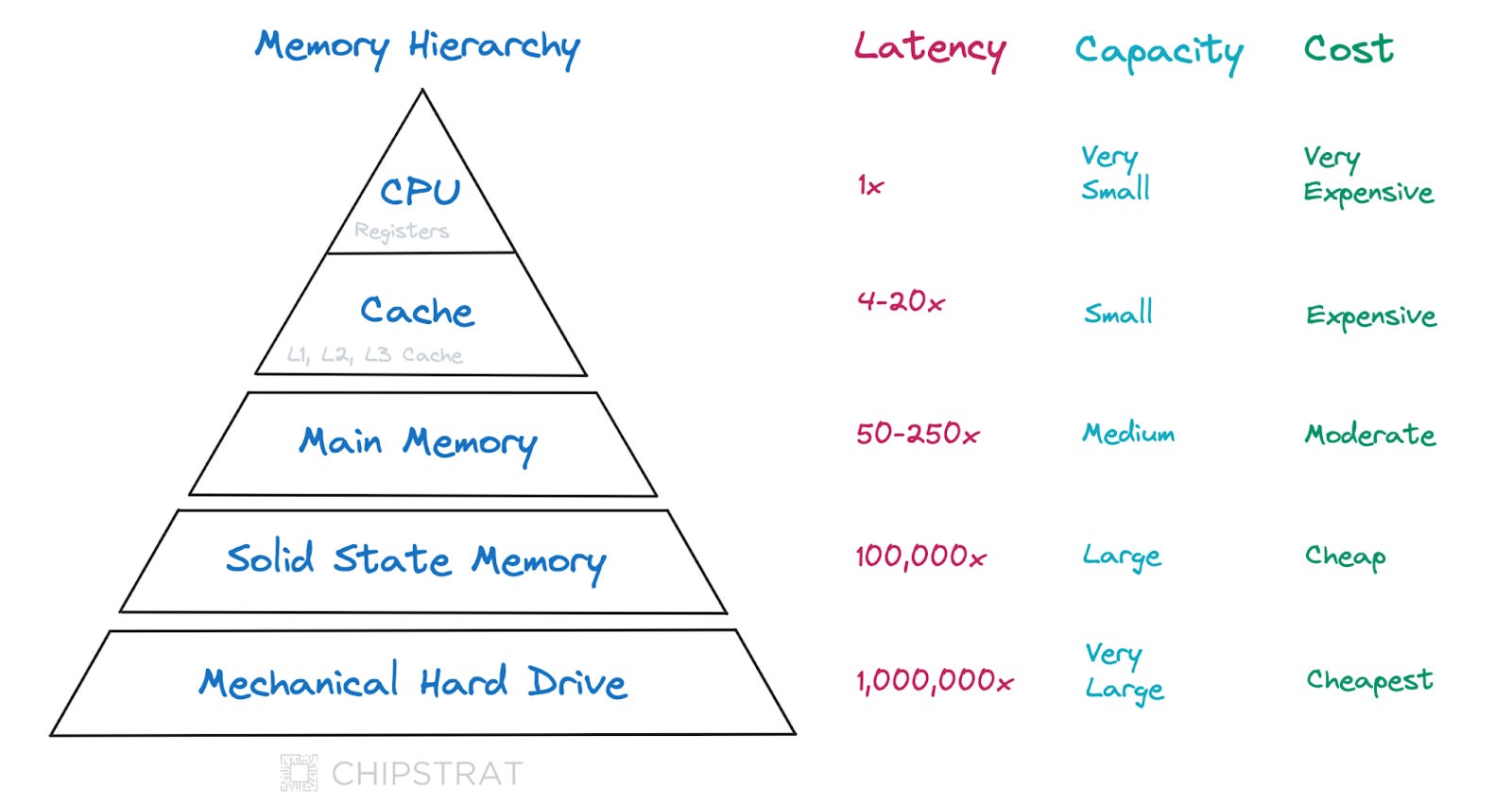
Memory Hierarchy
Like our book storage hierarchy, CPUs employ a memory hierarchy to ensure that frequently accessed information is readily available for quick retrieval.
Registers
CPUs keep data in registers for immediate access, akin to the desk in our analogy.
Registers are built using small, simple circuits known as flip-flops. You can find many great videos on YouTube if you’re curious to learn more about how flip-flops and registers work.
Cache Memory
CPUs use caches to keep additional data nearby, like the bookshelf from our analogy.
Instead of one cache, modern CPUs have a hierarchy of caches, descriptively named:
Level 1
Level 2
Level 3
A typical shorthand for these caches is L1, L2, L3 — i.e. “The L1 cache size is 64KB per core.”
This cache hierarchy is like a bookshelf hierarchy within our storage system. For example, a small bookshelf would be in the same room as the desk (L1), a larger bookshelf in the nearby room (L2), and a really big bookshelf in the basement or garage (L3).
Caches utilize Static Random-Access Memory (SRAM) due to its speed and reliability. However, SRAM is volatile, meaning it loses data when power is off; it’s like short-term memory.
SRAM’s higher cost and lower storage density than other memory types are attributed to its use of more transistors per cell (e.g., 4-6 transistors versus one transistor and a capacitor).
Main Memory
The system's main memory relies on Dynamic Random-Access Memory (DRAM), which is constructed with one transistor and one capacitor per bit and is also volatile. While not as fast as SRAM, DRAM's advantage lies in its high density and low cost per bit, making it suitable for storing large amounts of frequently accessed data.
Solid State Memory
Solid-state drives (SSDs) use non-volatile NAND flash memory to store data permanently. They provide faster access than hard disk drives and require no mechanical movement, allowing quicker retrieval and long-term storage of essential data and instructions, such as operating systems, applications, and user data.
Mechanical Hard Drive
Hard disk drives (HDDs) use magnetic storage technology, where data is written and read by a moving head to spinning disks. This mechanical process makes HDDs slower than SSDs but is cost-effective for storing vast amounts of data. These days, HDDs are typically used for backup and archival storage, where quick access is less crucial and significant storage capacity is beneficial.
Visualization
We can visualize a CPU’s memory hierarchy like this:
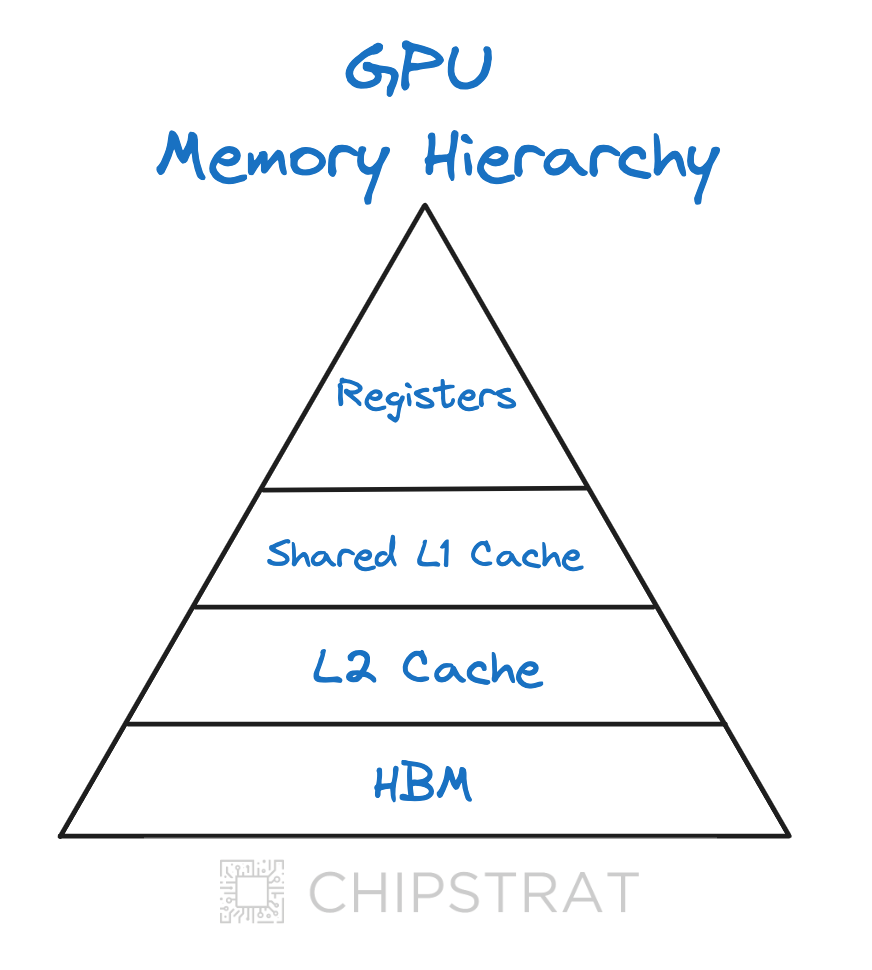
GPUs and HBM
CPUs aren’t the only ones with memory hierarchies. Parallel-processing systems, like Nvidia’s H100 GPUs, also employ a memory hierarchy.
Recall from our intro to GPUs that modern AI accelerator GPUs have thousands of cores and are optimized to maximize the amount of work they can do in a given time (throughput):
💡 CPUs are designed to minimize latency, whereas GPUs are tailored to maximize throughput.
As such, a GPU’s memory system is designed differently than a CPU.
GPUs require incredibly high memory bandwidth to keep all the cores supplied with data. As a reminder, bandwidth is the amount of data transferred in a given time.
High bandwidth is crucial because each core may perform similar operations on different data elements simultaneously, and any delay in data supply can bottleneck the entire process.
GPUs use a new type of memory called High Bandwidth Memory (HBM), which has significantly higher bandwidth than the main memory found in CPUs. Here’s a nice explainer video from AMD:
An example of an AI accelerator GPU memory hierarchy with HBM:
LLMs
Memory capacity can be a limiting factor in Generative AI. The best models struggle to fit on a single data center GPU, let alone an edge device NPU. The most advanced Large-Language Models (LLMs) require significant memory capacity to store the neural network’s weights; for example, Meta’s Llama 3 70B with FP8 is about 70GB. Thus, HBM capacity is one factor constraining the size and, therefore, the “intelligence” of LLMs deployed in a system.
Beyond storing the model's learned parameters, running an LLM requires additional memory resources for activations and other temporary data. Furthermore, during inference, LLMs utilize a key-value cache to store intermediate results, which expands with sequence length and can consume significant memory. Lastly, HBM capacity impacts batch processing capabilities, where larger batches improve throughput, performance, and the ability to run more substantial and capable models.
Memory Wall
Memory constraints are not unique to LLMs. Historically, memory performance has consistently lagged behind processor performance, creating a long-standing bottleneck affecting many workloads.
This lag is referred to as the “memory wall” or “memory gap” and can be traced back decades:
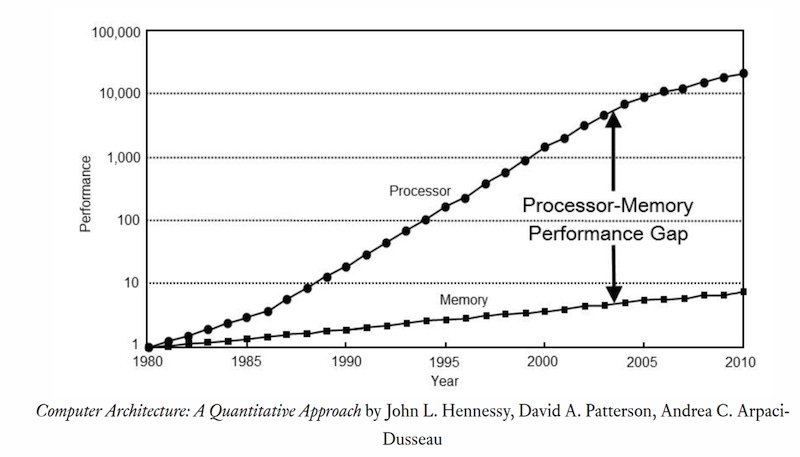
Unaddressed, this leads to a bottleneck in which CPUs increasingly find themselves idle while waiting for data to be retrieved from memory.
This imbalance arises because the shrinking of transistors doesn't boost memory performance as effectively as processing performance, especially for capacitor-based memories like DRAM.
While the pace of transistor scaling has slowed, progress in processor design continues through architectural innovations, such as adopting multi-core architectures. Memory manufacturers have also pursued similar architectural improvements to enhance performance. HBM, with its 3D vertical stacking, is a prime example of such innovation, enabling faster communication, reduced power consumption, and improved signal integrity by minimizing the distance data needs to travel.
The Business of Memory
Commodities
Unlike logic chips, memory chips are commoditized. This makes memory a tough business, driven by boom and bust cycles.
Why?
Let’s first define commodity.
A commodity is an economic good or product that is fungible, meaning it can be readily interchanged with other goods of the same type regardless of who produced it.
Commodities are typically standardized and widely used, and there is little differentiation between products made by different manufacturers. Thus, the price of a commodity is usually determined by overall market demand rather than by individual brands.
Think about agricultural commodities like corn. A bushel of corn from farmer A is the same as a bushel of corn from farmer B. There’s no differentiation. As such, the market sets the price.
Commodity producers, like farmers, are price-takers and not price-makers.
This fungibility leads to race-to-the-bottom pricing, as enterprise customers purchase primarily based on price rather than brand or specific features.
Commodity Cycle
The memory industry follows a "boom-bust" commodity cycle.
The cycle begins with a synchronized expansion of production capacity across competitors during periods of strong demand. When this capacity exceeds demand, prices and profits decline sharply, causing suppliers to reduce production and investment. This reduction in production eventually causes shortages, setting the stage for another round of expansion and perpetuating the cycle.
The memory industry's cyclical nature is partially rooted in its substantial fixed production costs. Building and maintaining semiconductor fabrication facilities (fabs) requires massive upfront investments, and these fixed costs create pressure to maximize output to achieve economies of scale.
Another factor is the long lead time to adapt production capacity. Expanding fabs or building new ones can take years, making it difficult for manufacturers to quickly adjust production to match fluctuating demand.
Visualizing the Cycle
I love the way Doug O’Laughlin at Fabricated Knowledge illustrates where he believes a particular industry is in the commodity cycle:
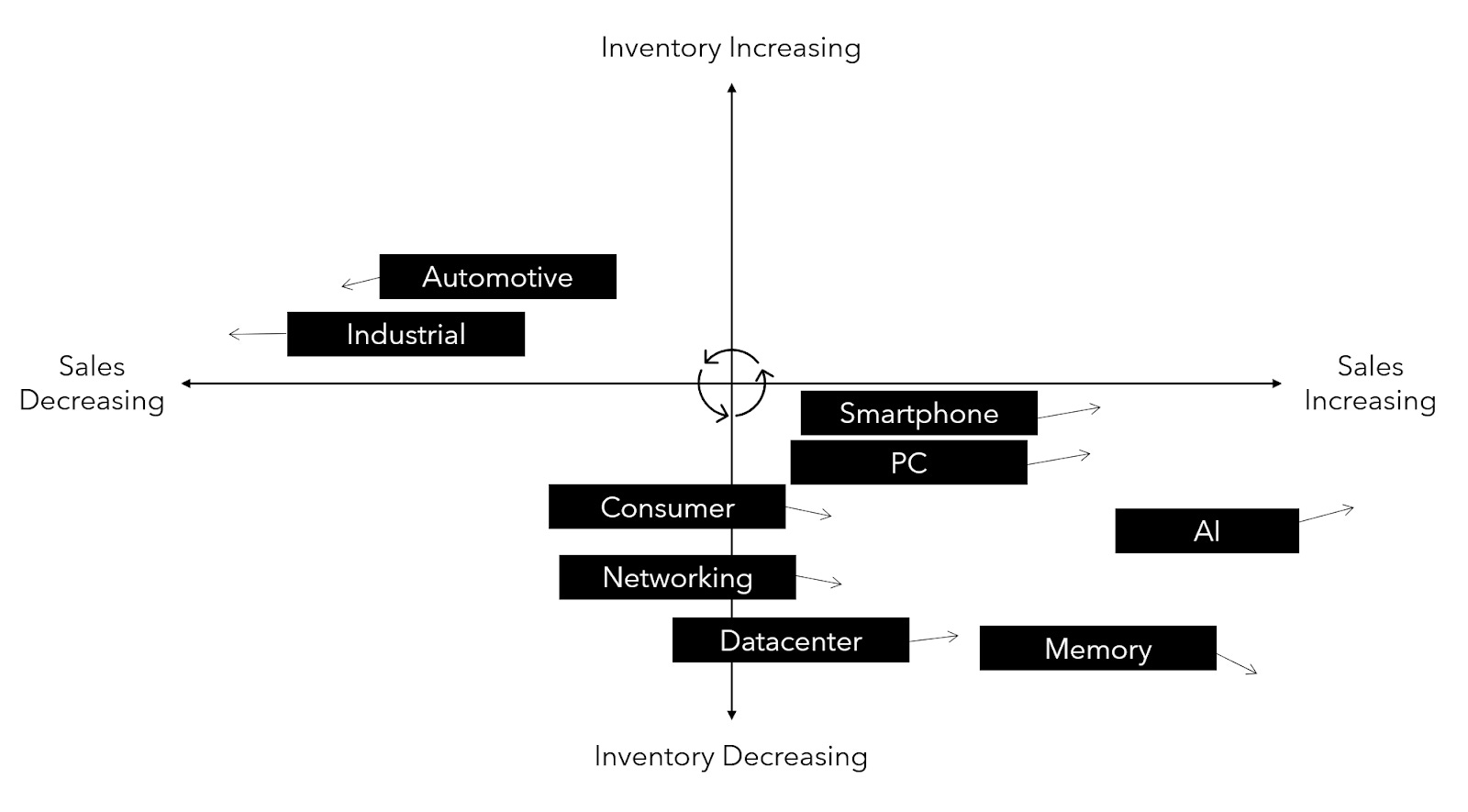
In this chart, Doug conveys memory’s increasing sales and decreasing inventory. This suggests that prices should rise as high demand and limited supply drive prices upward.
Building on Doug’s chart, we can generally visualize commodity cycles like this:
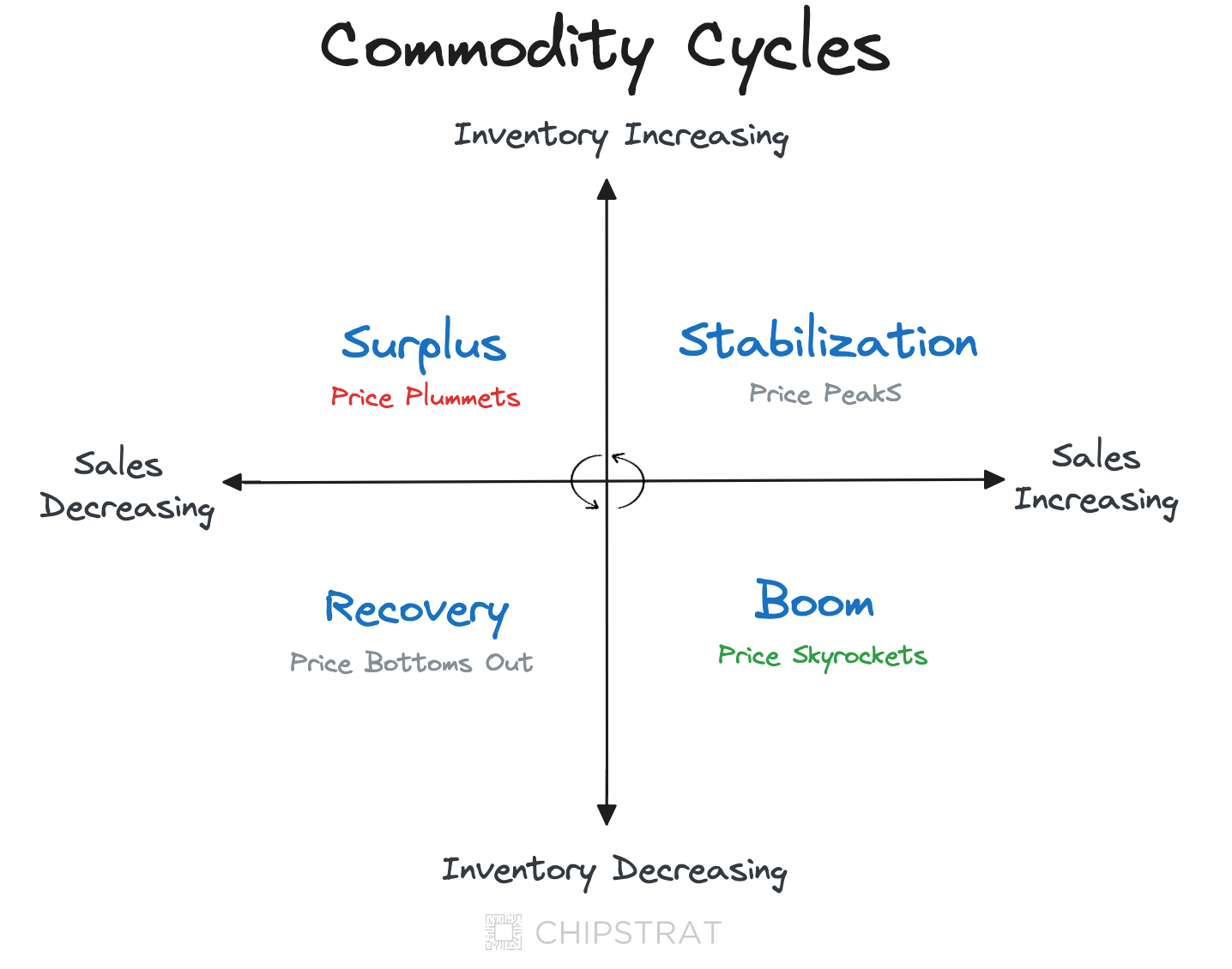
Each quadrant can be understood as follows:
Boom - This phase is characterized by high demand exceeding supply, driving prices up quickly. Manufacturers are likely operating at full capacity and struggling to keep up with orders. This is a profitable time for producers but can lead to buyer challenges, such as allocation (limited quantities per customer) or extended lead times.
Stabilization - As manufacturers ramp up production in response to the boom, inventory levels start to increase. However, sales growth may be slowing down as the initial surge in demand subsides. This leads to stabilizing prices as the market moves towards equilibrium.
Surplus - Inventory continues to accumulate as production outpaces slowing demand. This excess supply puts significant downward pressure on prices, which can fall rapidly. Manufacturers may be forced to cut production and lower prices to remain competitive, reducing profitability.
Recovery - Inventory levels start to decrease as sales pick up, indicating that the market is correcting itself. Prices may initially bottom out but will begin to increase as demand further outpaces supply. This phase signals the beginning of the next cycle, as manufacturers will likely ramp up production again in response to rising demand.
Memory History Lesson
The memory business's cyclical nature is deeply rooted in its history, as evidenced by Intel, DRAM's creator, eventually leaving the market.
This shift occurred as the DRAM business evolved from a value-add model, allowing Intel to command premium prices, into a commodity market characterized by intense price wars and shrinking profitability.
Winding back the clock, Intel’s innovation was on full display in their 1971 annual report:
Our leadership in the semiconductor market continued last year in both dollar sales and technology. New sales offices were established in Paris and Tokyo. We found widespread acceptance for our 1103 MOS memory circuit, a 1024-bit Random Access Memory (RAM) which was introduced in late 1970 and by late 1971 was an industry standard.
These strong 1103 sales helped us capture an estimated 30% to 50% of the available semiconductor memory market.
January 1971 we introduced the world's first non-destructively programmed Read Only Memory (ROM). This 2048-bit device, the 1601, is user-programmed by insertion of electrical charges into tiny Silicon Gate layers floating within the oxide layer. Where a charge is stored in one of the layers it causes the related transistor structure to read out as a binary "zero" with no diminution of the charge. Because of the great purity of the oxide layer the stored charge is effectively permanent in normal operations.
Non-destructive programming makes the 1601 extremely reliable because it's functionally tested before shipment and it doesn'trely on blown metal interconnections.
In August we updated this device with the 1701, having the added advantage of being both erasable and re-programmable. This was another industry first.
But things were bad by 1985:
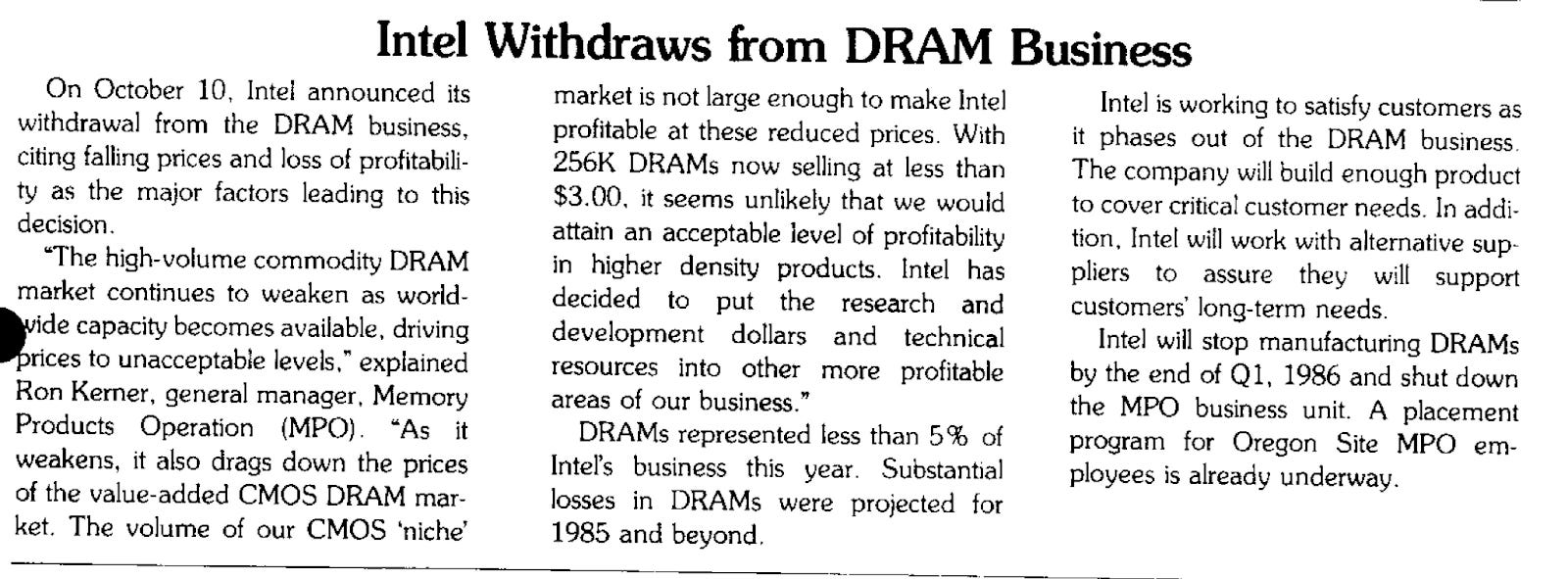
Fast-forward to today: Is HBM destined to follow in DRAM's footsteps, eventually becoming a commodity as the technology becomes more widespread and standardized?
Beyond Silicon
Will memory performance continue to increase?
As silicon-based devices shrink to near-atomic dimensions, quantum effects like tunneling and confinement cause power leakage, performance variability, and heat dissipation issues. Researchers have spent the past several decades investigating alternative materials and devices for logic and memory chips to overcome silicon's fundamental limitations imposed by quantum effects at nanoscale dimensions.
I spent a few fun years contributing to this topic during my Master’s studies at the University of Illinois Champaign Urbana in Prof. Eric Pop’s research group, investigating the usefulness of a two-dimensional material called graphene for next-generation transistors and memory.
In partnership with industry leaders like TSMC, Prof. Pop's research group has recently released promising findings on a novel memory technology. From Stanford Report,
Researchers at Stanford have demonstrated that a new material may make phase-change memory – which relies on switching between high and low resistance states to create the ones and zeroes of computer data – an improved option for future AI and data-centric systems. Their scalable technology, as detailed recently in Nature Communications, is fast, low-power, stable, long-lasting, and can be fabricated at temperatures compatible with commercial manufacturing.
The GST467 superlattice clears several important benchmarks. Phase change memory can sometimes drift over time – essentially the value of the ones and zeros can slowly shift – but their tests show that this memory is extremely stable. It also operates at below 1 volt, which is the goal for low-power technology, and is significantly faster than a typical solid-state drive.
“The unique composition of GST467 gives it a particularly fast switching speed,” said Asir Intisar Khan, who earned his doctorate in Pop’s lab and is co-lead author on the paper. “Integrating it within the superlattice structure in nanoscale devices enables low switching energy, gives us good endurance, very good stability, and makes it nonvolatile – it can retain its state for 10 years or longer.”
“The fabrication temperature is well below what you need,” Pop said. “People are talking about stacking memory in thousands of layers to increase density. This type of memory can enable such future 3D layering.”
Of course, there’s typically a long period between a proof-of-concept in the lab and mass production, if the technology makes it to the industry at all.
Yet research like this provides optimism for continued memory and logic performance advancements. The potential of emerging “beyond silicon” technologies suggests that the semiconductor industry's innovation era is far from over.