



Nvidia 4Q25 Earnings
Inference-First Deployments, Refresh Cycles, Ethernet, GPUs vs ASICs, and more

Nvidia’s 2025 earnings call was more revealing than it seemed. Is cost-per-token now the key battleground for AI infrastructure? Why is Nvidia pushing Ethernet, and what does that mean for Infiniband? What happens to aging GPUs? We’ll also explore Nvidia’s positioning against AI ASICs, revenue concentration risks, and whether AMD’s modularity can still be a differentiator. And if cost-per-token drives the market, can MI350 and MI400 compete with Nvidia’s ecosystem? We’ll unpack all of this, backed by key call quotes.
Inference-First Deployments
GPU purchases are mainly from leading cloud service providers (Microsoft, Amazon, Google, Oracle), hyperscalers (Meta, X), and smaller specialized GPU clouds like CoreWeave. It was previously believed that these entities would adopt next-generation Blackwell GPUs for training and reallocate older Hopper GPUs for inference.
However, CFO Colette Kress indicated otherwise:
CK: Blackwell supercharges reasoning AI models with up to 25x higher token throughput and 20x lower [inference] cost versus Hopper 100.
This underscores that inference on previous-generation GPUs is more expensive.
With inference now driven by cost-per-token efficiency, Blackwell’s dramatic cost reduction makes it the clear choice over Hopper for inference; legacy hardware reuse may not be as attractive as expected.
Does this mean less Blackwell for training?
Nope.
Sure, Ilya says pretraining scaling is dead, and GPT4.5’s “not a frontier model” seems to support that notion, yet post-training scaling is not dead, and maybe GPT4.5 is simply raising the floor and not the ceiling. There’s enough progress and uncertainty to buy more and better GPUs still.
More compelling is Grok 3, which showed us that pretraining scaling appears alive and well given that xAI can speedrun from incorporation to top-tier model in only 19 months thanks to 200K GPUs.

So, we’ll still have CapEx-laden infrastructure companies building 100K+ clusters for AI labs to train frontier models. That’s going to consume a lot of Blackwell supply.
But, again, Colette Kress said there’s an incentive to earmark new Blackwell shipments for inference, not just training:
CK: We've driven a 200x reduction in inference costs in just the last two years.
The takeaway is that newer GPUs have a lower inference TCO than the n-1 generation. (Well, unless the prior generation hardware is fully depreciated, but we haven’t made it a full depreciation cycle yet with Hopper.)
Blackwell’s gen-on-gen cost-efficiency gains are incentive enough, but don’t forget the bigger story: the exponential rise in token generation driven by reasoning models and inference-time scaling.
CK: Our inference demand is accelerating, driven by test time scaling and new reasoning models like OpenAI's o3, DeepSeek-R1, and Grok 3. Long-thinking reasoning AI can require 100x more compute per task compared to one-shot inferences.
Reasoning models can generate orders of magnitude more tokens!
AI inference demand is growing (ChatGPT's 400 million weekly active users) and token generation is increasing due to reasoning. This is forcing a focus on cost efficiency:
CK: Blackwell has great demand for inference. Many of the early GB200 deployments are earmarked for inference, a first for a new architecture.
There are serious incentives to buy Blackwell systems for both training and inference. No wonder Jensen says the demand for Blackwell is incredible.
Refresh Cycles
The next question, then, is what to do with older Hopper infrastructure?
Does the fact that Hopper is less cost-effective mean the chip's useful life is quite short? Will Hopper be cannibalized by Blackwell?
No and no, says Jensen. GPUs usefulness extends well beyond serving cost-effective production inference workloads or supporting the biggest training runs:
JH: We're also really good end-to-end, from data processing (the curation of the training data), to the training of the data, to reinforcement learning used in post-training, all the way to inference with test-time scaling.
Sure, inference as-a-service companies want the most efficient hardware serving production inference to reduce token costs. And yes, AI labs want the best hardware for their big training runs. But Hopper GPUs are still very useful to AI labs for other key R&D steps like data preparation, small experimental training runs, and post-training steps like distillation and RLHF.
I think of it like an aging NFL quarterback who might not have the same giddy-up-and-go anymore to be the starter, but is still useful on the team as a scout QB, backup quarterback, coach, etc.
Of course, Hoppers work totally fine for production inference too — they just cost more per token. Companies may not get enough Blackwells to fully meet their inference needs anyway, so they can still use Hoppers and simply take a margin hit or charge more. Look no further than GPT4.5 being wildly expensive and only accessible in certain regions, partially because “we’re out of GPUs”. When you’re capacity-constrained, Hoppers will do just fine.
Jensen went out of his way to suggest that GPUs have a longer lifecycle than expected.
JH: First of all, people are still using Voltas, Pascals, and Amperes.
Note — these are chips launched many years ago — 2016, 2017, 2020! I’m sure you can’t even buy Voltas and Pascals new anymore, and I wouldn’t be surprised if Ampere is nearing being discontinued.
If companies are still GPUs that are 4 to 8 years old, Hoppers will obviously still be used for some time. What else matters if the lifecycle is long?
JH: If the useful life is much longer, then the TCO is also lower.
Hopper’s useful life might even extend past the depreciation period, so companies can use them “for free”.
In summary, Nvidia made the case that
Next-gen chips will be preferred for training and inference
Previous-gen GPUs remain crucial for Gen AI workflows
GPU lifespans are theoretically longer than expected given the GPUs flexibility
Of course, the counterargument to #3 is that GPUs used for demanding tasks like AI training undergo accelerated wear due to high utilization. For example, during Meta’s Llama 3 training, GPU-related failures account for the majority of unexpected interruptions:
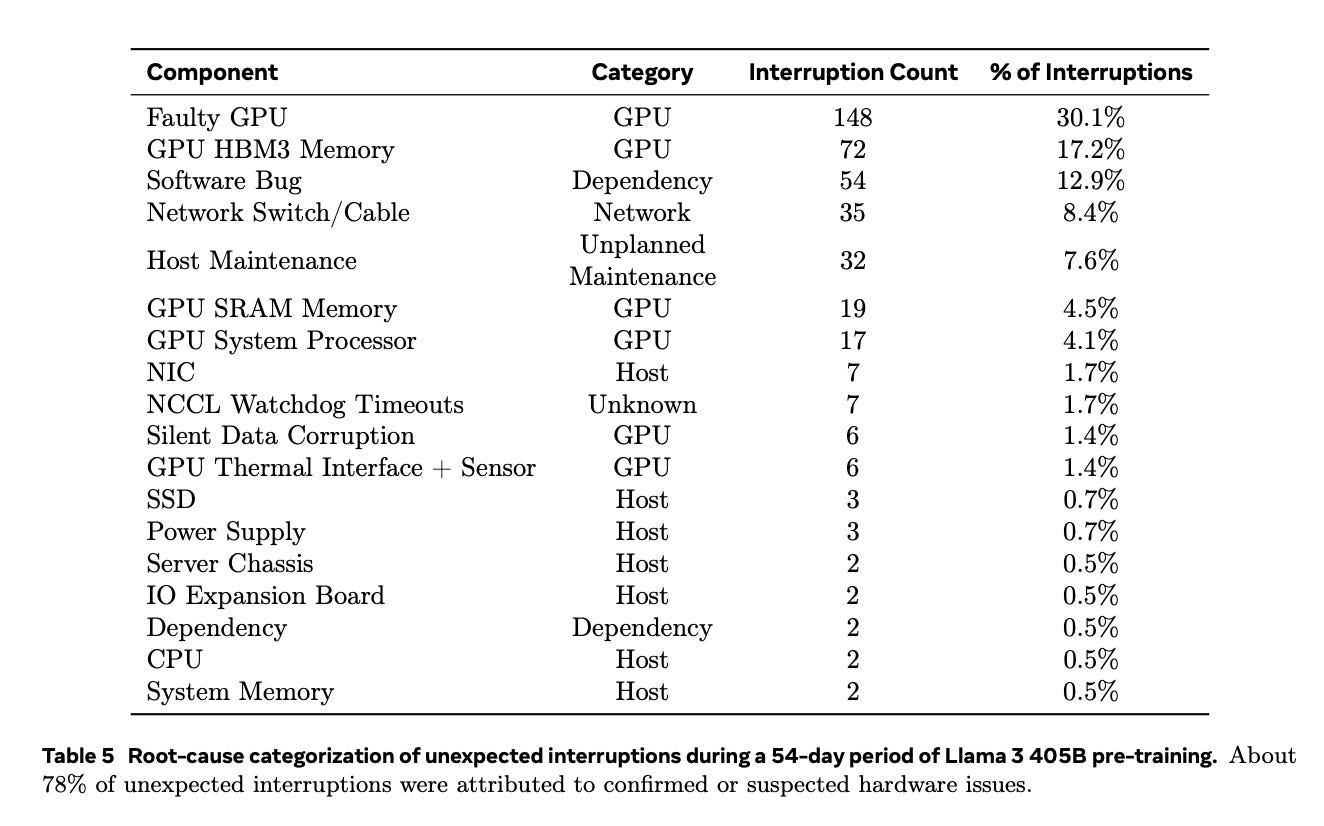
I would love to see data from big GPU customers regarding actual Hopper lifespans, e.g., a cohort analysis going back to 2022. What percentage of that fleet is still in use after 2 years, 3 years, and so on?
GPUs vs ASICs
Jensen and Colette spent a considerable amount of time positioning GPUs against ASICs.
Fungible
First, Nvidia pointed out that we have three different scaling laws—pre-training, post-training, and inference time—and Nvidia’s GPUs can happily serve them all.
JH: We defined Blackwell for this moment—a single platform that can easily transition from pre-training, post-training, and test-time scaling.
We’ve made this point again and again. GPUs are general-purpose and therefore fungible.
JH: Blackwell is going to be incredible across the board. And when you have a data center that allows you to configure and use your data center based on whether you are doing more pretraining now, post-training now, or scaling out your inference, our architecture is fungible and easy to use in all of those different ways.
Of course, some AI ASICs are more programmable than others, so they are similarly fungible. Google uses TPUs for training and inference. Anthropic uses AWS’ Trainium2 for low-latency inference and will use it for training See this video around the 39:50 mark.
Anthropic: Earlier this week, my colleague Tom was on stage at Peter DeSantis’s keynote, where he announced that we’re betting big on Tranium, especially Tranium2. We’re using Tranium2 for fast, low-latency Claude inference and working with AWS on a truly massive new Tranium2 training cluster called Project Rainier.
I wanted to explain in a little more detail why we made that choice—why we’re betting on Tranium. First and foremost, we’re looking for the best price-performance at the largest scale. Those are the core goals that matter most to us, and Tranium2 delivers great performance per dollar, especially on memory bandwidth-bound or memory bandwidth-sensitive workloads. On the scale side, we can rely on AWS for their world-class data center infrastructure experience. They’ve built for larger scale than anyone, and their expertise in large-scale capacity delivery is unmatched. This kind of cluster isn’t routine for anyone, but it’s the closest to routine for Amazon.
Over the last year, we’ve learned a lot about the Tranium2 chip architecture and really appreciate the flexibility and programmability of all the hardware engines in the neuron core. We can write low-level kernels that pipeline workloads across different engines to maximize tensor utilization and squeeze out the most performance possible. The Neuron Profiler that Ron demoed lets us see exactly what instructions execute when and where on the chip—almost no other accelerator can do that. That level of visibility gives us the tools we need to optimize all our workloads.
Lastly, we’re incredibly excited about the Ultra Server architecture and scaling out to support more kinds of parallelism on larger and larger models, both for LLM inference and LLM training.
Anthropic says Amazon’s Trainium AI ASIC can be used for training and inference too; it’s fungible to a certain extant. Anthropic also claims Trainium has better performance per dollar compared to Nvidia.
Yet Anthropic is funded by AWS and therefore highly motivated to invest the effort and opportunity cost needed overcome the switching costs of moving away from Nvidia. Honestly, Anthropic’s workloads can be thought of as AWS first-party workloads.
But what motivation does a 3rd party developer have to move to Trainium?
Anthropic included a subtle counterargument in this video — it will be increasingly easy to use AI to help write that code 😀 See the 46:15 mark in this video
Just for this demo, we hooked up Claude AI to the latency-optimized Tranium2 Haiku 3.5. We’re going to show a short video where I created a Claude project that includes all of the NKI documentation—programming guides, example kernels, architecture guides—essentially everything AWS has written about NKI and how to program in it.
The goal here is to teach Claude a new programming language it has never seen before since NKI is brand new, and we’ll see how it goes. We loaded all of this into its context window and then asked Claude to write a kernel for Softmax and explain each line. Right now, it’s processing and caching about 100,000 tokens of context on NKI, including all the example kernels. That step takes a few seconds, but once it’s done, it’s generating code much faster than Claude 3.5 and other models. In fact, it’s almost too fast to keep up with.
Maybe Softmax is too easy. Now, I’m pasting a description of an activation function that Anthropic introduced in an old blog post and asking Claude to write a kernel for that. This means it’s using a programming language it has never seen before to write a kernel for a function it’s just learning about today. I haven’t examined the output super closely yet, but it looks like it’s doing a solid job, and the code is coming out faster than we can even keep up with.
I’ll hand it back to Joe for the last part.
“Thanks, James. I just want to remind everyone that what we just saw was actually Tranium writing code to be used on Tranium—super exciting stuff.”
Obviously there’s still a lot of effort to switch, even with the help of AI, but it’s a good point nonetheless. And hey, with every passing month it should get easier and easier; maybe coding agents will progress to the point where they could meaningfully help port a codebase.
Now, don’t forget: not all AI ASICs are the same. Some are less programmable, some can’t support training, some don’t have significant HBM capacity to run big models. So don’t lump all AI ASICs together — just because Anthropic uses Trainium for a particular workload doesn’t mean OpenAI will use Microsoft Maia for similar workloads, etc. GPUs are the defacto until widely proven otherwise.
Roadmap Cadence
Jensen reminded listeners that Nvidia’s GPU-based systems are not only more adaptable than ASIC alternatives but also advance at a much faster rate. And it’s not just the chip roadmap, but the entire system—compute, networking, memory, and software.
JH: We’re general, we're end-to-end, and we're everywhere… Our rhythm is so incredibly fast. … bringing that whole ecosystem on top of multiple chips is hard.
Can AI ASIC roadmaps from AWS, Google, or startups move as quickly?
“If You Build It, They Will Come” Fallacy
Finally, my favorite point Jensen made from the entire call: sure, AI ASICs can outperform Nvidia GPUs on paper for certain workloads, but winning involves convincing internal and external customers to actually deploy them.
JH: And then finally, I will say this: just because the chip is designed doesn't mean it gets deployed. And you've seen this over and over again. There are a lot of chips that get built, but when the time comes, a business decision has to be made, and that business decision is about deploying a new engine, a new processor into a limited AI factory in size, in power, and in fine. And our technology is not only more advanced, more performance, it has much, much better software capability and very importantly, our ability to deploy is lightning fast. These things are enough for the faint of heart, as everybody knows now.
When I listened to the call my first response was “oh, sick burn!” Hey, where are all those startup AI ASIC chips? Where’s Microsoft Maia? All I see in these hyperscaler datacenters is Nvidia!
But after coming back to the transcript I see it more like grandfatherly wisdom from a seasoned vet to startups and internal ASIC teams. Hey guys, this industry is much more than “the fastest chip wins”. Anyone can design a fast chip. The hard part is convincing enough customers to allocate their precious engineering time and datacenter space to run your systems. Is your system promising enough to offset the opportunity cost of simply buying more Nvidia?
We’re proud of the Field of Dreams here in Iowa, and it made for a great line in the movie, but don’t listen to that voice:
Nvidia’s Ethernet
Nvidia’s AI training performance owes much to its Infiniband networking, acquired through the Mellanox acquisition, which enables efficient scale out. Yet Nvidia’s customers increasingly want Ethernet — it’s cheaper, they’re familiar with it, and it’s plenty suitable for inference.
Rather than ceding AI networking dollars to Broadcom, Nvidia responded by creating SpectrumX Ethernet, optimized specifically for AI workloads. This fits Nvidia’s broader system-level strategy: optimize every piece of the system for AI workloads.
This was a good business move. The call highlighted the customer demand for Ethernet, which Nvidia is capturing.
CK: For scale-out, we offer Quantum-X800 Infiniband and Spectrum X for Ethernet environments. Spectrum-X enhances the Ethernet for AI computing and has been a huge success. Microsoft Azure, OCI, CoreWeave, and others are building large AI factories with Spectrum-X. The first Stargate data centers will use Spectrum-X.
These are major players choosing Ethernet over Infiniband. I think this is increasingly driven by inference cost optimization.
Nvidia’s scale out is seemingly moving toward Ethernet, possibly as the default scale out networking technology instead of InfiniBand?
CK: Our networking attached to GPU compute systems is robust at over 75%. We are transitioning from small NVLink 8 with InfiniBand, to large NVLink 72 with Spectrum-X.
Another interesting business move in networking: Nvidia is expanding Spectrum-X outside of their own portfolio, in partnership with Cisco.
Yesterday, Cisco announced integrating Spectrum-X into their networking portfolio to help enterprises build AI infrastructure. With its large enterprise footprint and global reach, Cisco will bring NVIDIA Ethernet to every industry.
Nvidia’s original networking push with Infiniband served hyperscalers running massive AI training workloads. They are currently catering to at-scale inference workloads with SpectrumX. Where does Cisco fit in?
Partnering with Cisco gives Nvidia an entry into enterprise data centers, easing AI adoption for IT teams already accustomed to Cisco’s networking solutions. I’m not sure the on-prem market is massive, but it’s still additive for Nvidia.
Paywall
Behind the paywall we’ll cover some of the more interesting points, including:
Why Nvidia’s revenue is more concentrated than it appears
Jensen’s vision for software is correct but the timing may be off
How Nvidia is undercutting a key AMD advantage
Why AMD can compete against Nvidia’s previous-gen GPUs