

Reasoning Models and DeepSeek, Semis Implications
Reasoning Models, Compute Demand, Scaling Laws, Competition

Much ink has already been spilled about DeepSeek, yet the conversation tends to skew either highly technical or completely surface-level. This research report delivers an accessible yet technically grounded analysis of the DeepSeek R1 paper, highlighting its implications for the semiconductor industry.
Let’s start with context, and then we’ll unpack key paragraphs from the paper.
Here’s a quick overview video you can watch.
Or this full post as audio:
The full written article below.
The Basics of Reasoning
First, from DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning:
“In the context of reasoning capabilities, OpenAI’s o1 (OpenAI, 2024b) series models were the first to introduce inference-time scaling by increasing the length of the Chain-of-Thought reasoning process”
Recall that OpenAI’s GPT-style models quickly respond with the first answer that comes to mind; a mental model here is thinking fast. In contrast, reasoning models like o1 take a more deliberate approach, carefully unpacking problems, checking intermediate steps, and ensuring logical consistency — thinking slow.
As noted in the DeepSeek paper, o1 employs a Chain-of-Thought (CoT) reasoning process. A helpful way to think about CoT is as an internal dialogue—the model engages in self-conversation before answering, allowing it to explore different approaches and refine its response.

When the paper mentions
increasing the length of the Chain-of-Thought reasoning process
we can think of this as letting the model talk to itself for longer. OpenAI discovered that the longer its model spends thinking, the better the results. Makes sense!
This phenomenon is called inference-time scaling or test-time scaling.
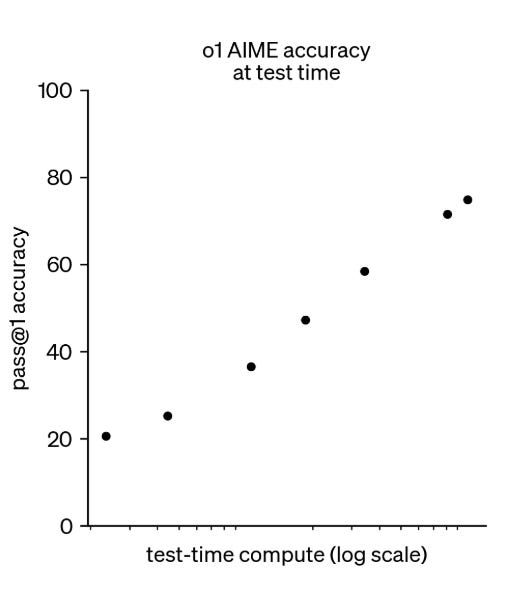
Notice that giving the model more time to think allows it to demonstrate more of its inherent intelligence. It appears less capable if forced to respond instantly, but with extended reasoning time (more compute!), it performs at a much higher level. The key takeaway is that the model itself doesn’t change—it’s already pretrained—but allocating more compute during inference improves its intelligence.
This compute knob could be dialed up and down per request, user, or organization.
We haven’t even touched DeepSeek yet, but from OpenAI’s reasoning models, we can already make interesting observations.
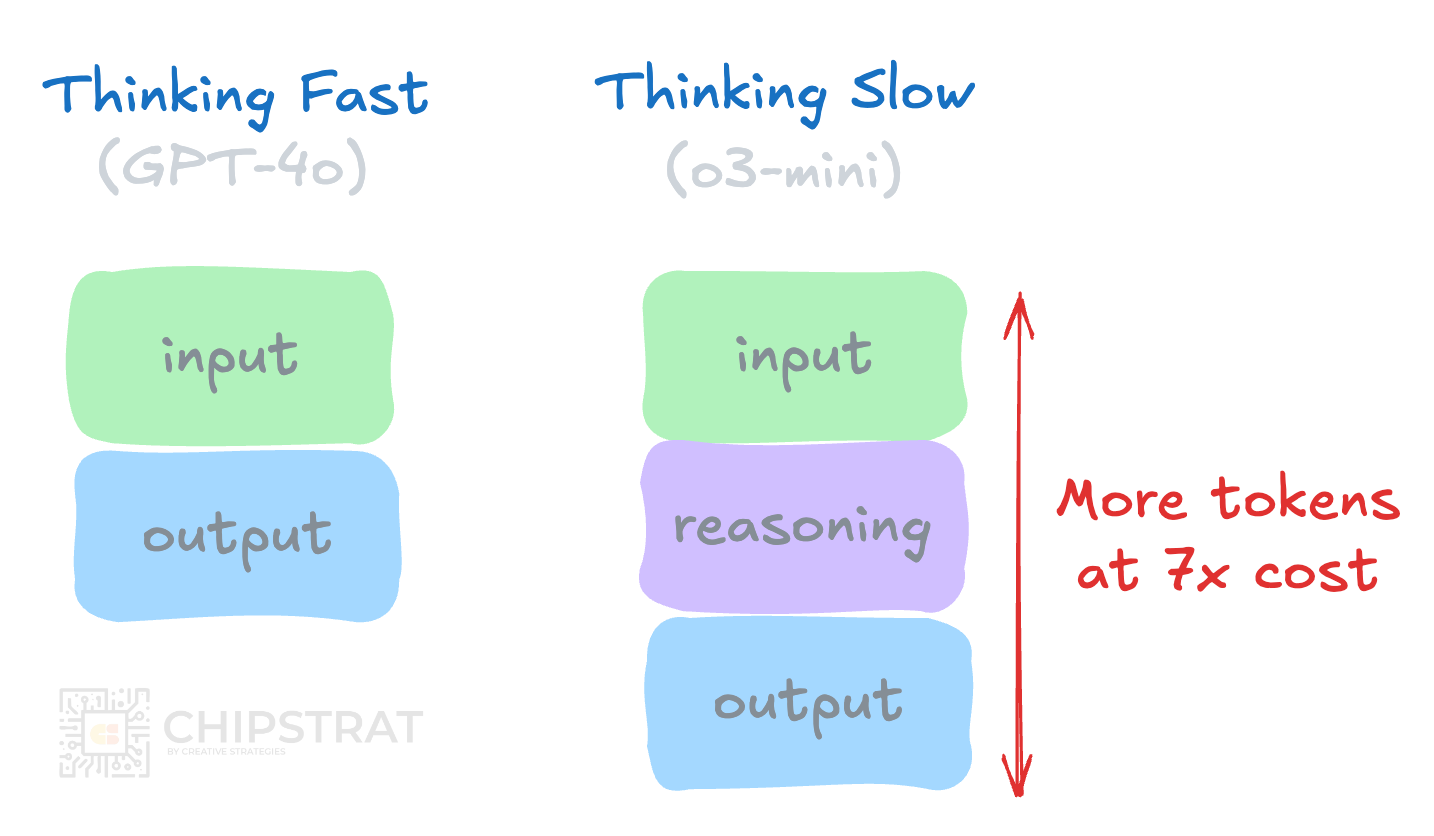
First, reasoning models use a lot of computation! Specifically, they generate a lot of tokens (internal dialogue) while reasoning, which can be turned up or down per the use case and business model.
Inference-time scaling is a new demand vector for AI compute; until o1, all GPU demand before September 2024 was driven by scaling compute, training data, and model size during pretraining, per the OpenAI 2020 paper Scaling Laws for Neural Language Models.

The GPT “thinking fast” models were computationally expensive to train but cheap to use; clusters with thousands of GPUs were necessary for massive training runs, but inference could run on an 8-GPU server. Of course you’d need to scale up your inference cluster to serve a larger amount of simultaneous users, but the point is that 10K GPU purchases were only necessary for the few companies training foundation models.
However, reasoning models can be computationally expensive to use. Sure, you can also fit the reasoning model on an 8-GPU server, but the reasoning model might use those GPUs for 20 seconds of “thinking” per user request now!
Thus, reasoning inference requires more compute per user.
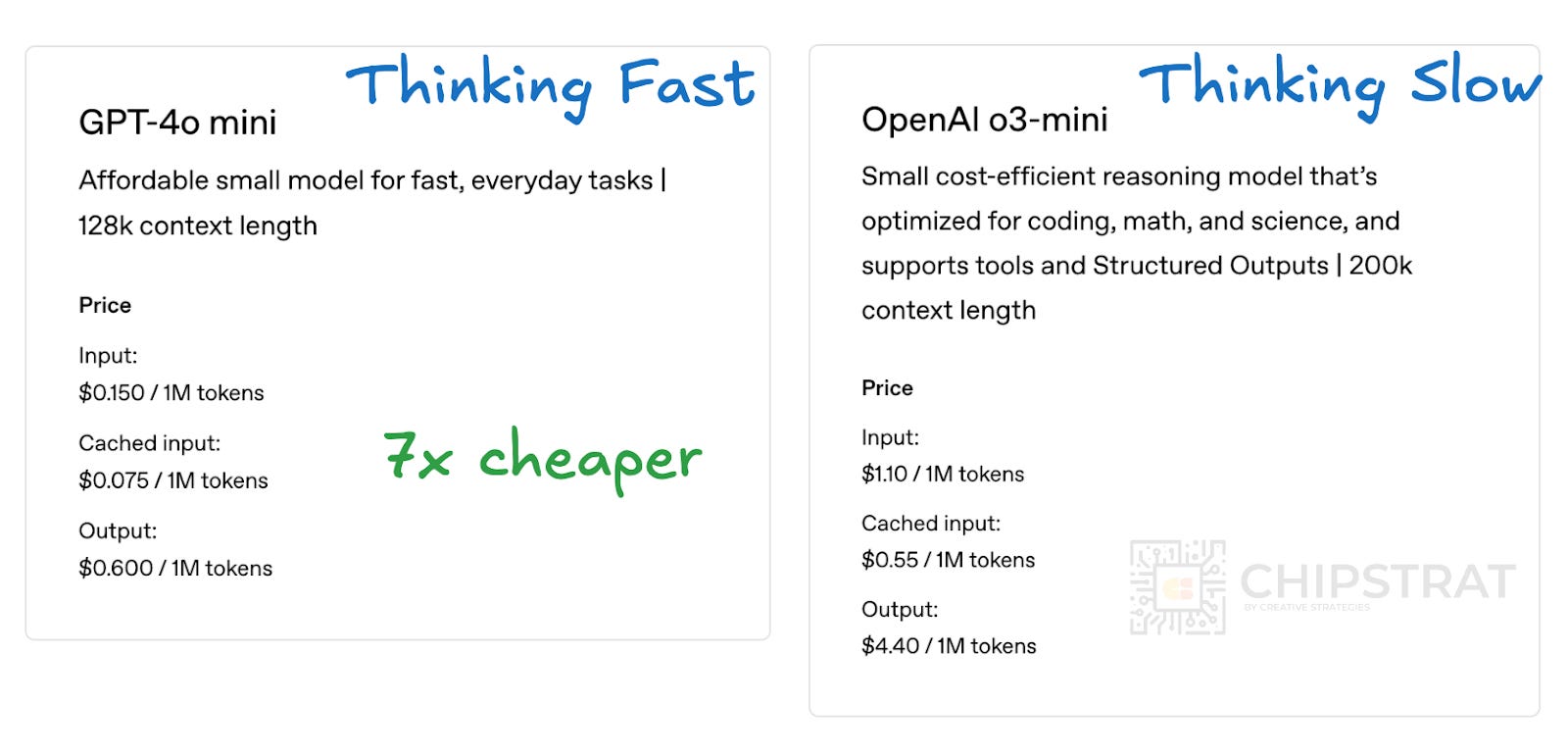
This heavy GPU usage for reasoning is reflected in higher prices for customers. Take OpenAI’s API fees for cloud-based reasoning services:
Back to the DeepSeek paper:
[OpenAI’s] reasoning approach has achieved significant improvements in various reasoning tasks, such as mathematics, coding, and scientific reasoning
OpenAI’s reasoning process was developed to help LLMs solve challenging and quantitative problems that benefit from thinking slowly. Simple memory retrieval tasks (“What’s the capital of Spain?”) don’t require reasoning — this is what the “thinking fast” GPT models are great at.
It’s vital to understand when to use a particular model type because using the wrong model can be expensive. As we saw, o3-mini API access is 7.3X higher priced; if you need a quick answer, get it faster and cheaper with GPT-4o!
Even though reasoning models are derived from “fast thinking” models, their deliberative approach isn’t always beneficial; they can occasionally overcomplicate problems or arrive at incorrect answers due to unnecessary reasoning steps. A wrong answer is terrible, but thinking too long is also bad!
With the advent of different model types comes friction for API developers who have to manually choose between fast-thinking and slow-thinking models.
Ideally, developers would have an option where OpenAI automatically decides whether to use the fast, low-cost model or the slower, more expensive reasoning model based on the prompt. While it wouldn’t be perfect every time, many developers might prefer this tradeoff over manually handling model selection.
Worse, this “model selection” UX pain exists for consumers, too.
Have these designers ever talked to a consumer outside of Silicon Valley? Hey Mom, give this AI thing a try! Just pick the model from this list…

It’s not just OpenAI either:

Developing A Reasoning Model
When OpenAI created a reasoning model, they likely started with a base model and used reinforcement learning (RL), possibly with Supervised Fine Tuning (SFT) or RLHF. Given that they are a product company and thus aren’t open with their AI, the o1 announcement didn’t go into much detail:
Our large-scale reinforcement learning algorithm teaches the model how to think productively using its chain of thought in a highly data-efficient training process.
Given what we learn from R1, we can assume it was something like this:
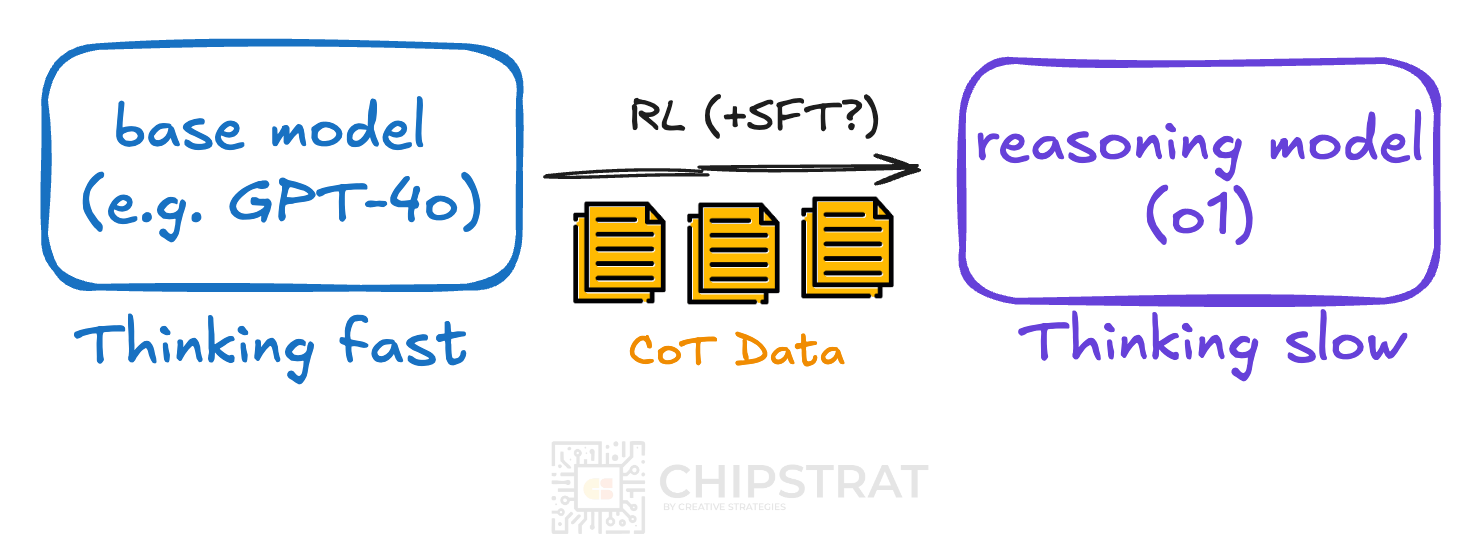
The process starts with a base model and a high-quality, chain-of-thought dataset. Human annotators create this dataset, documenting their reasoning steps to arrive at answers (like students showing their work). Each example is also labeled with quality metrics (e.g., correctness, coherence, completeness, and alignment with human preferences). These examples are used to train the model to reason effectively.
This data creation is a significant undertaking, often requiring dedicated annotation services like those provided by ScaleAI. However, OpenAI gave hints that their “highly data-efficient training process” didn’t need a ton of curated data.
Finally, reinforcement learning refines the model's reasoning using a reward model to evaluate its internal dialogue based on factors like correctness, clarity, and efficiency.
DeepSeek’s innovation is that they didn’t need any supervised fine-tuning on chain of thought data, but simply “pure” RL:
Our goal is to explore the potential of LLMs to develop reasoning capabilities without any supervised data, focusing on their self-evolution through a pure RL process. Specifically, we use DeepSeek-V3-Base as the base model and employ GRPO (Shao et al., 2024) as the RL framework to improve model performance in reasoning.
We can picture this process as:

(Recall that DeepSeek V3 is the cost-efficient model that got everyone all excited in the first place).
Note the absence of the curated data set during this reasoning training run. Surprisingly, reasoning simply emerges from the RL process; no example Chain-of-Thought data is needed! OpenAI may have discovered this first, but DeepSeek is the first to share it with the world:
Notably, it is the first open research to validate that reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT.
That said, the resulting R1-Zero model had issues:
However, DeepSeek-R1-Zero encounters challenges such as poor readability, and language mixing.
The DeepSeek team ended up needing chain-of-thought example data to get a satisfactory model, which they call DeepSeek R1:
To address these issues and further enhance reasoning performance, we introduce DeepSeek-R1, which incorporates a small amount of cold-start data and a multi-stage training pipeline. Specifically, we begin by collecting thousands of cold-start data to fine-tune the DeepSeek-V3-Base model. Following this, we perform reasoning-oriented RL like DeepSeek-R1-Zero.
… After these steps, we obtained a checkpoint referred to as DeepSeek-R1, which achieves performance on par with OpenAI-o1-1217.
At a very high level, we’ve got a process that looks similar to OpenAI’s o1 process:

Note that DeepSeek also had a very data-efficient process like o1, using only “thousands of cold-start data” reasoning samples and ~800K synthetic samples, i.e. training data generated by DeepSeek’s V3 and R1-Zero models. The takeaway here is that DeepSeek demonstrated it’s neither super expensive nor time-consuming to gather sufficient data for reasoning training. This implies that other research labs can also develop reasoning without requiring deep pockets.
Small Reasoning Models
Lastly, DeepSeek showed they transfer the ability to reason from their R1 model to much smaller dense models. This is the most important innovation from the paper in my opinion.
First, they used the big reasoning model to generate more chain-of-thought training data. Then, they performed Supervised Fine-Tuning with this data on existing small models from Meta and Alibaba:

The process worked! The resulting small models can reason, and their performance is decent — in the ballpark to o1-mini!

What excites me is that DeepSeek’s small reasoning models have one trick that o1-mini doesn’t: they’re allowed to run at the edge.

DeepSeek's R1 models are small and efficient enough to run on devices like MacBooks and iPhones, bringing on-device AI to reality sooner than expected. Reasoning is essential for building local agent-like applications (i.e. do this task for me on my laptop).
Implications
Reasoning Models and Scaling
Recall that OpenAI identified another scaling law during reinforcement learning: more compute during RL leads to better reasoning performance. They call this train-time scaling.

That makes three scaling laws for reasoning models — two training and one inference:
Pretraining scaling (original scaling law circa 2020)
Train-time scaling (more time thinking during RL)
Test-time scaling (more time thinking during inference)
Note that Ilya says pretraining scaling is dead because we’re unable to scale training data:
“We’ve achieved peak data and there’ll be no more,” according to Sutskever. “We have to deal with the data that we have. There’s only one internet.”
Yet reasoning models can benefit from more compute time during reasoning training:

These models also benefit from more compute during inference:

Thanks to many optimizations, DeepSeek’s base (V3) and reasoning (R1) models demonstrated very efficient training and inferencing. Efficiencies drive an increased level of intelligence output per dollar invested.
Yet nothing from DeepSeek’s reasoning paper suggests that scaling laws are dead:
Pretraining scaling: improving the training efficiency of base model (e.g. V3) means the industry can eke out more intelligence gains per dollar invested. If your 10K GPU datacenter could unlock a certain level of intelligence before, with more efficient training methods from the V3 paper (FP8, Mixture-of-Experts, multi-token prediction, etc), the same compute may unlock a higher level of intelligence. Yes, training data is largely the industry bottleneck right now, but that doesn’t imply the industry wants to stay at this level of intelligence.
Train-time (RL) scaling: with DeepSeek’s open-sourcing of their models and approach, we can expect increased RL compute demand as other labs develop reasoning models
Test-time (inference) scaling: same as #2 — more labs can now build reasoning models, so we will see more inference scaling across the industry and, therefore, more inference compute utilization.
So take heart! DeepSeek does not negate these three scaling laws for datacenter training and inference.
As a final reminder — increased training and inference efficiency means more intelligence output for a given dollar input. This is nothing new: Nvidia is constantly maximizing training and inference performance per dollar spent through hardware, software, and networking innovations.

Still, there are nuances, especially with reasoning at the edge. More implications behind the paywall.