

ZML's Hardware-Agnostic Distributed Inference
Contemplating the trade-offs and implications

I recently saw an interesting Linkedin post from French startup ZML demonstrating vendor-agnostic Llama 2 inference. The demo leveraged pipeline parallelism to distribute the inference across hardware from Nvidia, AMD, and Google. Each chip was housed in a separate location, and the inference results were streamed back to the Mac that kicked off the job. Check out the video on the original post.

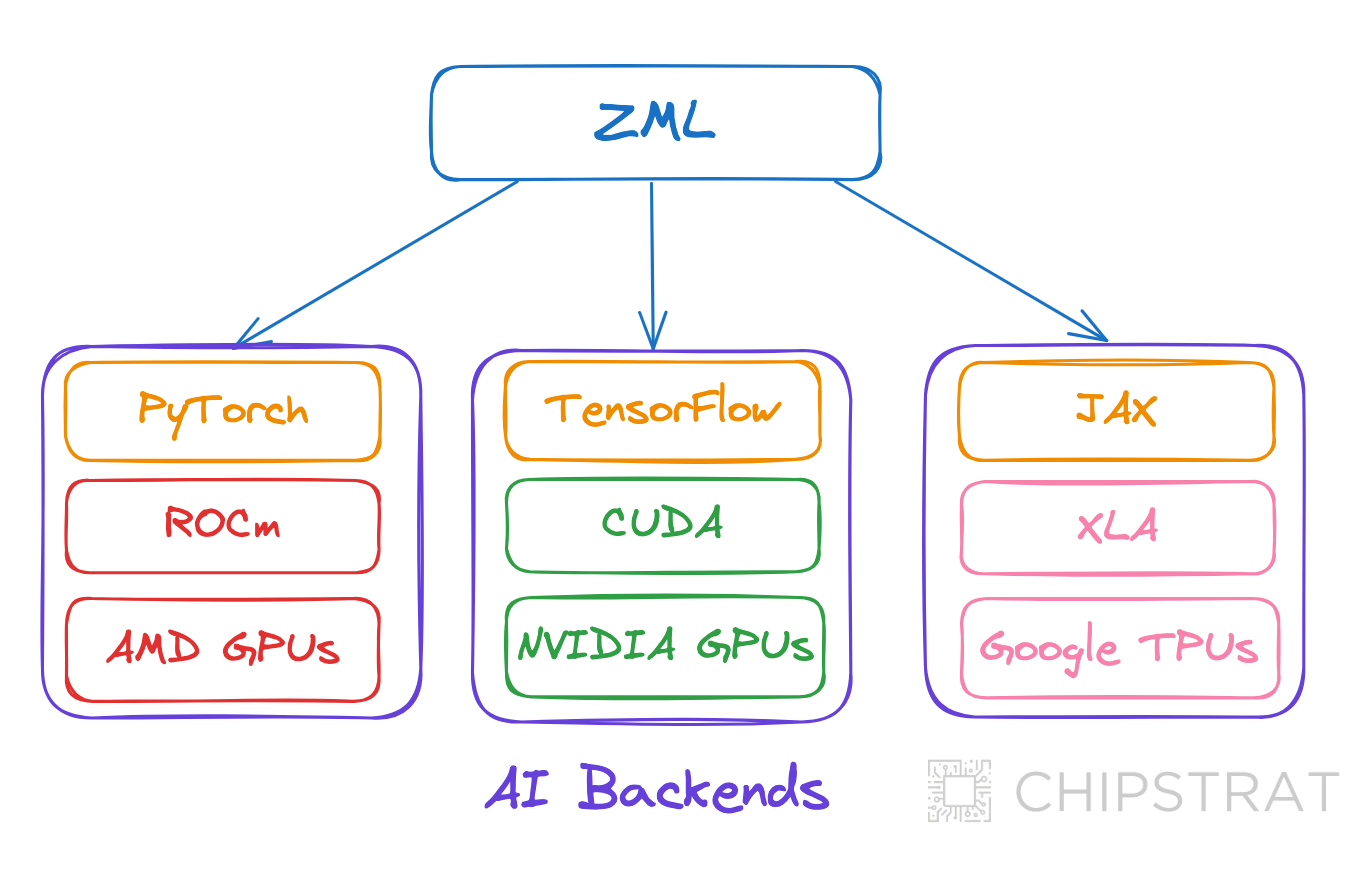
The standout feature of this demo is its hardware agnosticism, allowing a single codebase to run seamlessly across three distinct hardware platforms. I saw mention of “platforms” named zml/cuda, zml/rocm, and zml/tpu, hinting that this software may run on any CUDA hardware (H100, A100, etc) and any ROCm hardware like MI300X.
The point of the demo is not latency or throughput but rather the distribution of a deep neural network across separate hardware instances from different vendors. Yet despite using consumer hardware and contending with network latency, the responsiveness of the demo is surprisingly reasonable: 255 output tokens were streamed in maybe 4 or 5 seconds. This is good enough for tasks where lightning-fast response times aren't critical.
Why did ZML use consumer graphics cards and not H100s/MI300s? I’m guessing cost; gaming cards are a much cheaper development platform for a stealth startup.
Non-Traditional AI Clusters
Pooling less powerful GPUs together for training and inference is interesting in its own right.
Tiny Corp from George Hotz sells Tinybox systems that combine six gaming graphics cards into a local AI and training and inference cluster.

Sure, training Resnet with a tinybox might take 5-10x longer than the state-of-the-art GPUs it’s benchmarked against on MLPerf, but it’s also 10-20x cheaper. This raises the question of which uses cases might optimize for cost and accept slower training or inference is acceptable? I think a lot of internal use cases (back-office, data science, etc) could work around slower inference.
Meanwhile, others are tinkering with running inference on a cluster of Apple silicon.
ExoLabs makes it possible to distribute inference across Apple silicon. This example shows Llama3 405B distributed across 23 Mac Minis on the same network!
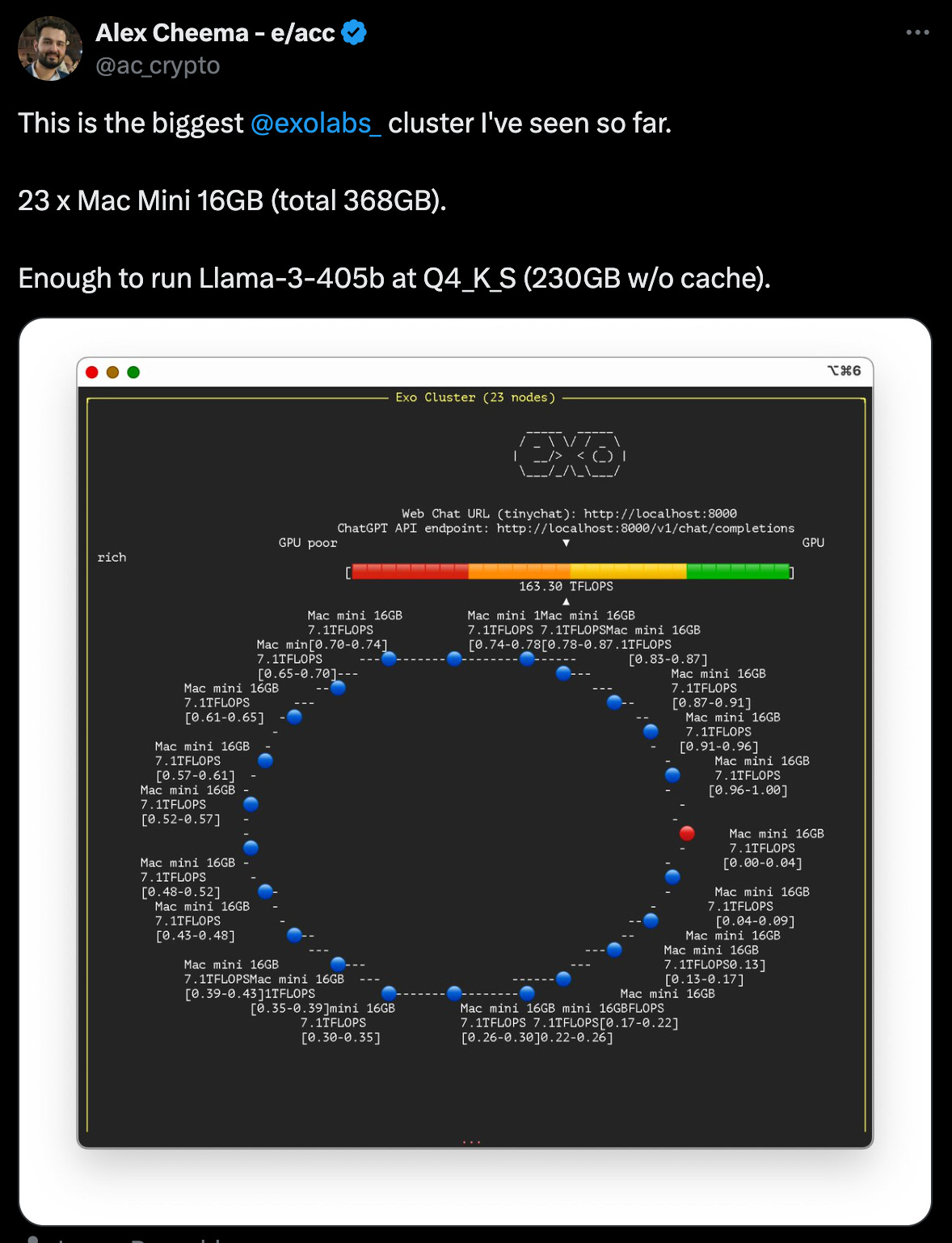
They also demonstrate running inference on a personal Apple cluster with an iPhone, iPad, and Mac.
If money is no object, you can even connect high-end Mac Studios via Thunderbolt:

ZML Difference
The tinybox and Apple silicon examples demonstrate single-vendor clusters using edge devices on the same local network.
What’s interesting about ZML is that it can support a multi-vendor cluster using cloud or edge hardware and doesn’t require physical proximity. ZML’s demo ran on hardware in two residential locations across Paris and a third TPU in a Google cloud somewhere in Europe.
This hardware and location agnosticism unlocks interesting use cases.
First, imagine shifting workloads across cloud instances based on pricing and availability. I’m not just talking about easily shifting between spot instances from a single Nvidia neo-cloud like CoreWeave; companies could distribute the workloads across multiple clouds like AMD-based TensorWave, too.
Second, enterprises could easily manage workloads across their aging, mixed fleet. Of course they could train on B200s and run inference workloads across old H100 and A100 clusters, but also add other cost-optimized vendors to the fleet. Hey, Dell called and they’re having a Gaudi 3 firesale. Let’s throw some into the mix, we can use them for reserve capacity and internal workloads.
Again, the hardware doesn’t need to be colocated, but spare compute could be utilized from any internal or external data center regardless of vendor.
ZML continues to raise the abstraction layer.
An Accelerator Cloud That Owns No Accelerators
Let’s assume that many of today’s enterprises have low GPU utilization as they’re still figuring out how to deploy generative AI meaningfully and profitably for their customers. What if the company could easily rent out a portion of its idle infrastructure in the interim?
Here’s an idea: ZML’s demo suggests the existence of an mixed-fleet accelerator cloud company that owns no accelerators is possible. Suppliers could rent out their hardware, and renters could schedule their workloads for any available accelerator regardless of vendor. The renters would need to sprinkle in the abstraction layer like ZML, and suppliers simply make sure their hardware is supported.
After some digging, I found that a few others are already doing this Airbnb for AI accelerators, but without the hardware-agnostic enabling software like ZML.
From VastAI
Don't let idle time be a cost burden; let it be a new revenue stream… We connect you with customers and provide simple tools to streamline hosting. Set your own prices and schedules. We handle the marketing and get clients so you can focus on the hardware.
And Akash
Akash is an open network that lets users buy and sell computing resources securely and efficiently… Become an Akash Provider by offering your hardware on the network and earn when users deploy.
Again, these companies are missing that ZML-like software layer that allows customers to run across a mixed fleet.
Playing skeptic — given the dominance of H100, it’s hard to imagine much demand for flexibly running across hardware from multiple vendors right now. Furthermore, what are the odds we actually see many vendors in the long run? Isn’t the semiconductor supply chain mostly just a few players in each layer of the stack?
For a mixed-fleet world, I think we’d need a future with a broad supply of AI accelerators on the market (Nvidia, AMD, Intel, startups), a massive demand for inference, and the accelerator hardware would need to be commoditized.
Or instead of commoditization, maybe there’s several niches with a few different competitive vendors, i.e. I want to rent Nvidia or AMD for my training workloads, Etched or Groq for customer-facing low-latency LLM inference workloads, AMD or previous-gen Nvidia for cost-optimized internal inference workloads, and so on.
Ideas aside, ZML hasn’t provided any information about its plans or business model yet. I’m really interested to see what they come up with.
Concerns and Tradeoffs of Hardware-Agnostic Inference
The best performance comes from tightly integrated and highly optimized systems. ZML's distributed approach surely sacrifices speed as a result of networking, and likely runs less optimized code for the given underlying hardware. It’s unclear how what level of control this type of software would give users over the underlying hardware; does ZML’s compiler magically optimize for the underlying hardware, or can they easily pass configuration of the underlying hardware to the user? e.g., here’s my Nvidia config file, AMD config file, etc.
The loss of control could be worth it for some hybrid architecture use cases. Companies could combine the best of both worlds: hand-tuned performance where needed, and abstracted but cost-efficient scaling everywhere else.
Lastly, the idea of easily moving workloads across any hardware has blockchain-like decentralization vibes. ZML’s demo hints at a future where coalitions of people, enterprises, or governments could pool compute resources to counterbalance today’s hypercentralization.
Do we really only want the world’s AI compute to be owned by a few big companies, many of which are controlled by a single powerful founder?
ZML is quite stealthy, but their demo was anything but.